Questo articolo è la seconda parte della mini-serie che descrive come implementare l’analisi delle performance degli asset con Python usando i metodi resi disponibili dal pacchetto “ffn – Financial Functions“.
Nel precedente articolo abbiamo introdotto i concetti basi della libreria e descritto l’oggetto PerformanceStats di FFN. In questo articolo ci concentriamo sull’oggetto GroupStats. Il PerformanceStats si usa con una singola serie di dati, mentre il GroupStats può usare un dataframe composto da più colonne che rappresentano contemporaneamente diverse serie di prezzi/equity.
Analisi di un gruppo di serie dati
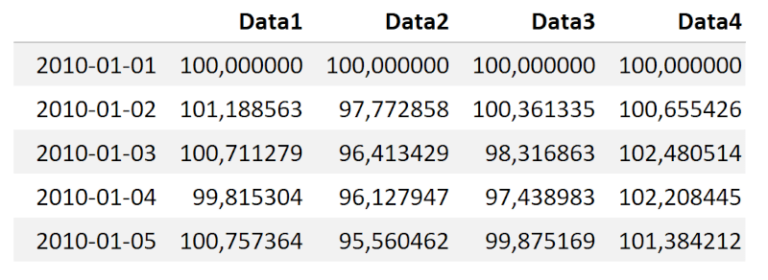
Creiamo ora alcuni nuovi dati. In questo esempio prevediamo un DataFrame con 4 colonne di dati, ciascuna delle quali rappresenta una “curva equity” di una strategia di trading (o del prezzo di asset) e visualizziamo le prime 5 righe di tali dati.
import pandas as pd
import numpy as np
np.random.seed(1)
num_days = 1000
index = pd.date_range('01/01/2010', periods=num_days, freq='D')
data1 = pd.DataFrame((np.random.randn(num_days) + np.random.uniform(low=0.0, high=0.2, size=num_days)),index=index,columns=['Data1'])
data2 = pd.DataFrame((np.random.randn(num_days) + np.random.uniform(low=0.0, high=0.2, size=num_days)),index=index,columns=['Data2'])
data3 = pd.DataFrame((np.random.randn(num_days) + np.random.uniform(low=0.0, high=0.2, size=num_days)),index=index,columns=['Data3'])
data4 = pd.DataFrame((np.random.randn(num_days) + np.random.uniform(low=0.0, high=0.2, size=num_days)),index=index,columns=['Data4'])
data = pd.concat([data1,data2,data3,data4],axis=1)
data = data.cumsum() + 100
data.iloc[0] = 100
print(data.head())
data e lo trasformiamo in un oggetto di ffn, in questo caso in un oggetto GroupStats e lo assegniamo ad una variabile.
import ffn
perf = data.calc_stats()
ffn.core.GroupStats. Ricordiamoci che nel caso di una singola serie di rendimenti abbiamo creato un oggetto ffn.core.PerformanceStats.
print(type(perf))
<classe 'ffn.core.GroupStats'>
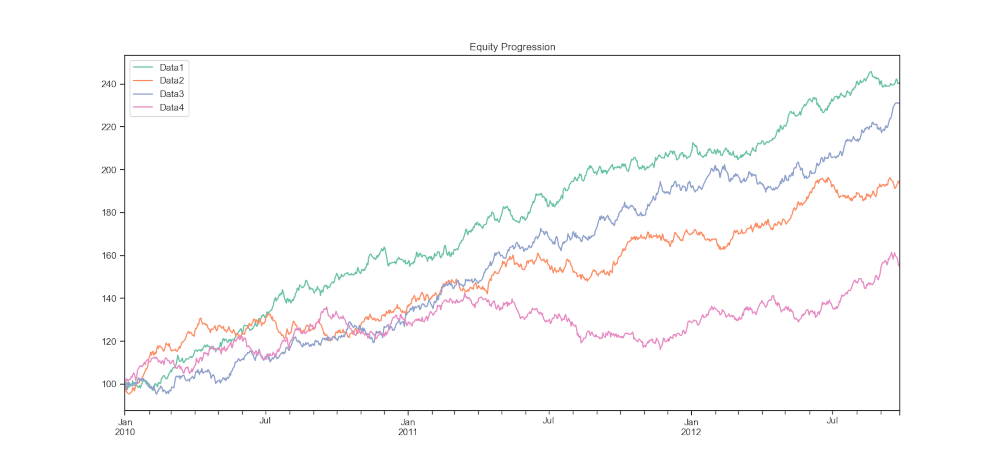
Possiamo quindi visualizzare il grafico dei rendimenti di questo gruppo di serie
perf.plot()
Analisi degli asset azionari
Vediamo ora come applicare queste funzioni ad un dataframe pandas che contiene le serie di prezzi storici di titoli azionari che scarichiamo da Yahoo Finance
import yfinance as yf
stocks = ['AAPL', 'AMZN', 'MSFT', 'NFLX']
data = yf.download(stocks, start='2010-01-01', end='2020-01-01')['Adj Close']
data.sort_index(ascending=True, inplace=True)
perf = data.calc_stats()
Se visualizziamo il grafico dei prezzi notiamo che sono automaticamente normalizzati ad un valore iniziale pari a 100 in modo da renderli più comparabili.
perf.plot()
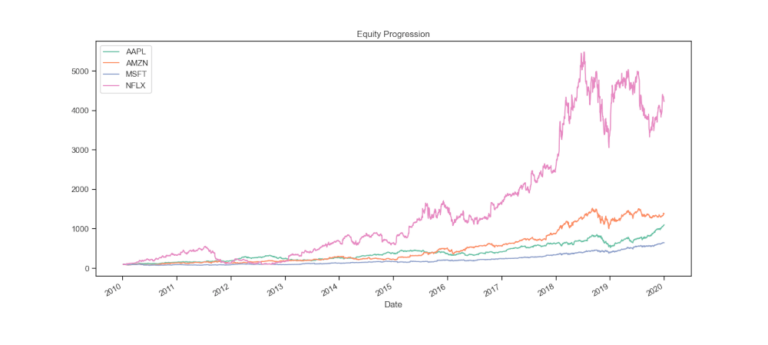
Iniziamo ad usare i dati storici dei prezzi dei titoli azionari appena scaricati per elaborare le statistiche e procedere ad analisi dettagliate. Ad esempio possiamo visualizzare le statistiche per tutti i titoli contemporaneamente tramite la stessa funzione, come descritto per una singola serie.
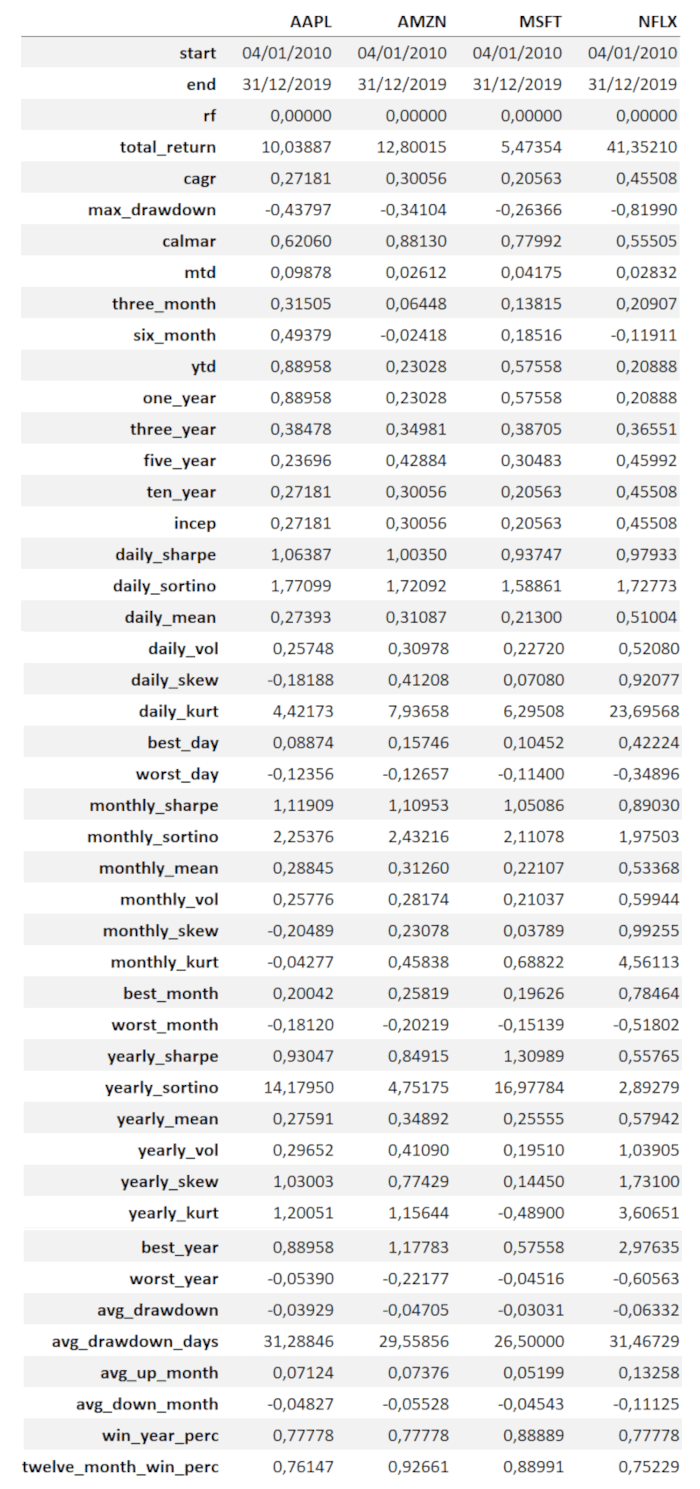
perf.display()
Stat AAPL AMZN MSFT NFLX
------------------- ---------- ---------- ---------- ----------
Start 2010-01-04 2010-01-04 2010-01-04 2010-01-04
End 2019-12-31 2019-12-31 2019-12-31 2019-12-31
Risk-free rate 0.00% 0.00% 0.00% 0.00%
Total Return 1003.89% 1280.01% 547.35% 4135.21%
Daily Sharpe 1.06 1.00 0.94 0.98
Daily Sortino 1.77 1.72 1.59 1.73
CAGR 27.18% 30.06% 20.56% 45.51%
Max Drawdown -43.80% -34.10% -26.37% -81.99%
Calmar Ratio 0.62 0.88 0.78 0.56
MTD 9.88% 2.61% 4.17% 2.83%
3m 31.50% 6.45% 13.81% 20.91%
6m 49.38% -2.42% 18.52% -11.91%
YTD 88.96% 23.03% 57.56% 20.89%
1Y 88.96% 23.03% 57.56% 20.89%
3Y (ann.) 38.48% 34.98% 38.70% 36.55%
5Y (ann.) 23.70% 42.88% 30.48% 45.99%
10Y (ann.) 27.18% 30.06% 20.56% 45.51%
Since Incep. (ann.) 27.18% 30.06% 20.56% 45.51%
Daily Sharpe 1.06 1.00 0.94 0.98
Daily Sortino 1.77 1.72 1.59 1.73
Daily Mean (ann.) 27.39% 31.09% 21.30% 51.00%
Daily Vol (ann.) 25.75% 30.98% 22.72% 52.08%
Daily Skew -0.18 0.41 0.07 0.92
Daily Kurt 4.42 7.94 6.30 23.70
Best Day 8.87% 15.75% 10.45% 42.22%
Worst Day -12.36% -12.66% -11.40% -34.90%
Monthly Sharpe 1.12 1.11 1.05 0.89
Monthly Sortino 2.25 2.43 2.11 1.98
Monthly Mean (ann.) 28.85% 31.26% 22.11% 53.37%
Monthly Vol (ann.) 25.78% 28.17% 21.04% 59.94%
Monthly Skew -0.20 0.23 0.04 0.99
Monthly Kurt -0.04 0.46 0.69 4.56
Best Month 20.04% 25.82% 19.63% 78.46%
Worst Month -18.12% -20.22% -15.14% -51.80%
Yearly Sharpe 0.93 0.85 1.31 0.56
Yearly Sortino 14.18 4.75 16.98 2.89
Yearly Mean 27.59% 34.89% 25.56% 57.94%
Yearly Vol 29.65% 41.09% 19.51% 103.90%
Yearly Skew 1.03 0.77 0.14 1.73
Yearly Kurt 1.20 1.16 -0.49 3.61
Best Year 88.96% 117.78% 57.56% 297.63%
Worst Year -5.39% -22.18% -4.52% -60.56%
Avg. Drawdown -3.93% -4.70% -3.03% -6.33%
Avg. Drawdown Days 31.29 29.56 26.50 31.47
Avg. Up Month 7.12% 7.38% 5.20% 13.26%
Avg. Down Month -4.83% -5.53% -4.54% -11.13%
Win Year % 77.78% 77.78% 88.89% 77.78%
Win 12m % 76.15% 92.66% 88.99% 75.23%
stats, quindi possibile essere indicizzato come qualsiasi dataframe.
print(perf.stats)
E può essere indicizzato, ad esempio, come segue.
print(perf.stats.loc['cagr'])
AAPL 0.271807
AMZN 0.300556
MSFT 0.20563
NFLX 0.455084
Name: cagr, dtype: object
Fino ad ora abbiamo visto come l’oggetto GroupStats generi output molto simile all’oggetto PerformanceStats. Descriviamo quindi alcune , quindi alcune funzionalità specifiche di GroupStats.
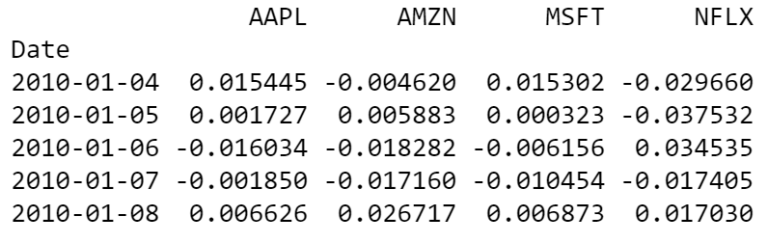
Iniziamo creando un DataFrame contenente una serie di rendimenti logaritmici per ciascuna delle equity dei prezzi delle azioni nel nostro DataFrame data.
returns = data.to_log_returns().dropna()
print(returns.head())
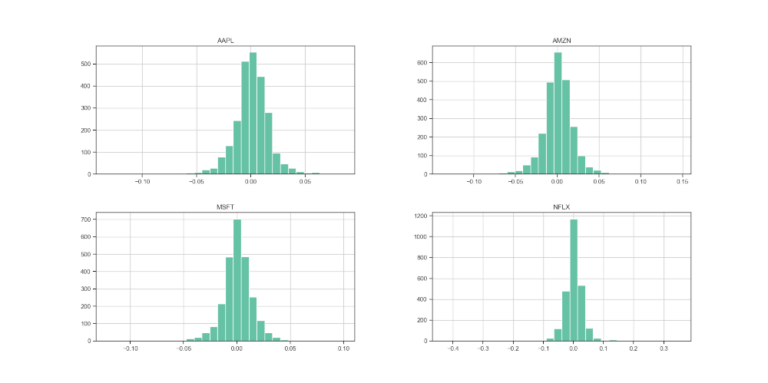
Possiamo creare rapidamente un multiplot degli istogrammi dei rendimenti logaritmici di ogni serie insieme allo screting di un dataframe contenente anche la matrice di correlazione dei titoli.
ax = returns.hist(figsize=(20, 10),bins=30)
print(returns.corr().as_format('.2f'))
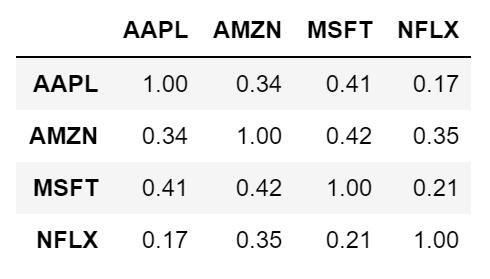
Funzionalità avanzate
Se vogliamo qualcosa di visivamente più accattivante rispetto allla stampa del dataframe, possiamo facilmente creare una heatmap della matrice di correlazione.
returns.plot_corr_heatmap()
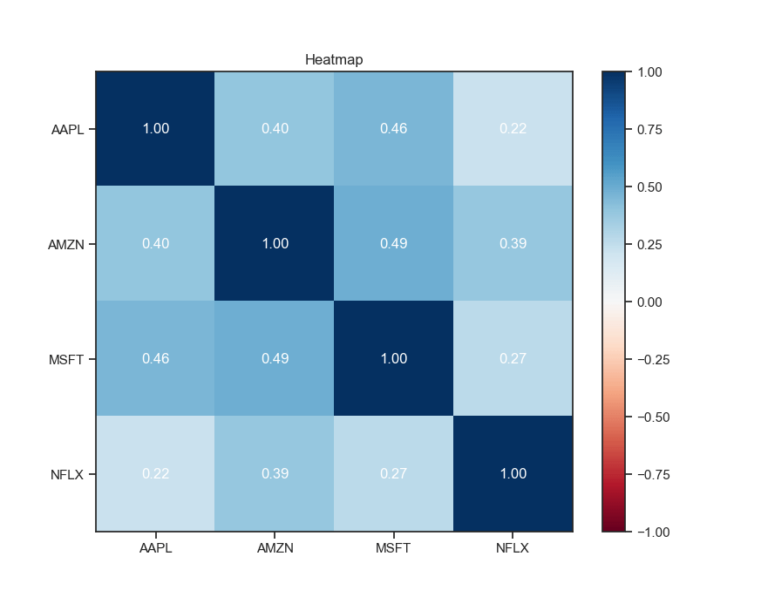
Questa heatmap mostra risultati un po’ più rilevanti rispetto ai precedenti dati generati casualmente. Continuiamo a usare i dati scaricati da Yahoo Finance per generare rapidamente il “portafoglio ottimale” basato sui classici metodi di Mean/Variance Optimisation di Markowitz.
print(returns.calc_mean_var_weights().as_format('.2%'))
AAPL 41.14%
AMZN 19.40%
MSFT 25.13%
NFLX 14.32%
dtype: object
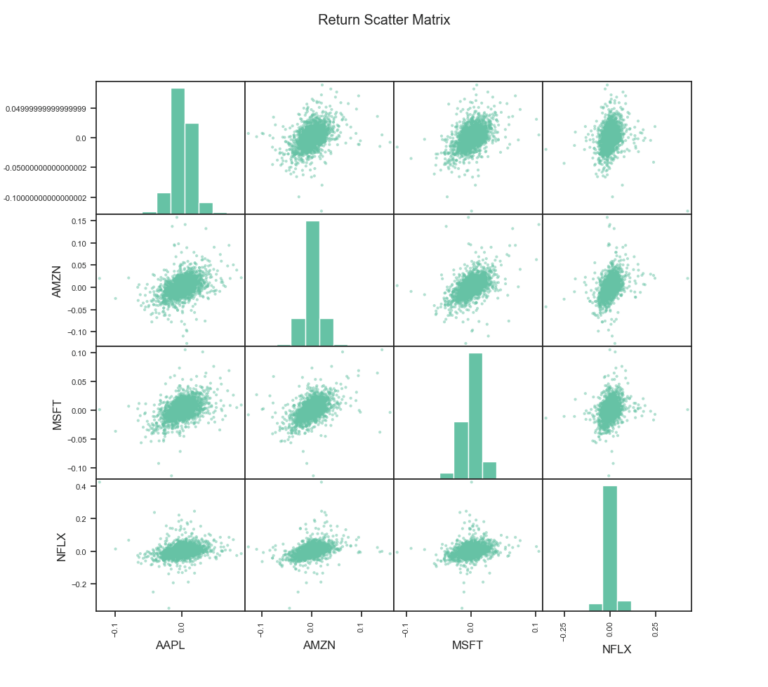
E’ possibile creare una completa matrice di grafici a dispersione con un semplice funzione.
perf.plot_scatter_matrix()
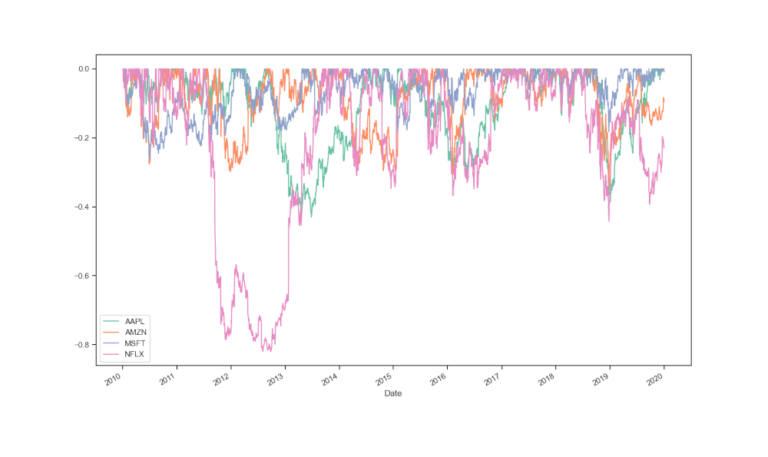
Possiamo anche visualizzare contemporaneamente le serie dei drawdown per tutti gli asset con la seguente funzione.
ffn.to_drawdown_series(data).plot(figsize=(15,10))
Ci sono ulteriori funzionalità disponibili dal pacchetto FFN, ma lascerò a voi tutti la possibilità di approfondire e testare le altre parti della libreria.
Codice completo
In questo articolo abbiamo descritto come implementare l’analisi delle performance degli asset con Python. Per il codice completo riportato in questo articolo, si può consultare il seguente repository di github:
https://github.com/datatrading-info/AnalisiDatiFinanziari