Nell’articolo precedente abbiamo installato Python e configurato il nostro ambiente virtuale. Abbiamo quindi utilizzato pandas-datareader direttamente nel terminale Python per importare alcuni dati OHLC azionari e tracciare cinque anni della serie storica dei prezzi di chiusura di un titolo azionario in poche righe di codice. Tuttavia, quando chiudiamo il terminale perdiamo tutti i dati. In questo articolo descriviamo come configurare un ambiente di prototipazione per il trading algoritmico con Jupyter per analizzare i nostri dati in modo riproducibile. Le librerie che usiamo in questo tutorial sono:
- Matplotlib v3.5
- Panda v1.4
- panda-datareader v0.10
- jupyter v1.0
- plotly v5.6
- ipykernel v6.4
Per lo scopo di questo tutorial abbiamo creato un ambiente Python utilizzando Python v3.8. L’installazione di Anaconda include il notebook Jupyter pronto all’uso. Puoi leggere il precedente articolo se non hai installato Anaconda.
Per iniziare dobbiamo entrare nell’ambiente di base e digitare jupyter notebook da qualsiasi directory e nel browser si apre una finestra che mostra tutti i file e le cartelle che si trovano in quella directory. Da questa pagina è possibile creare un notebook facendo clic su “nuovo”.
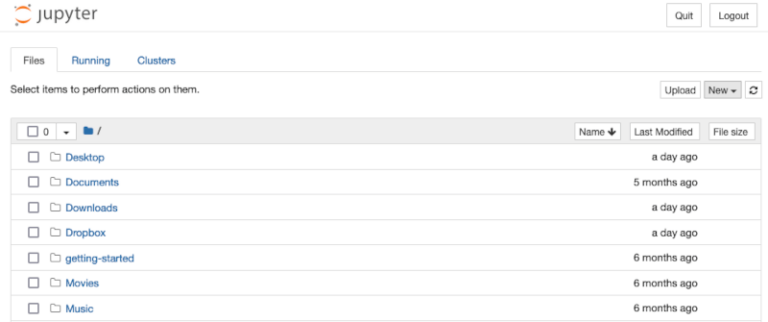
Dato che abbiamo eseguito jupyter notebook nell’ambiente “base” di anaconda abbiamo accesso a tutti i pacchetti Python installati in quell’ambiente. Tuttavia, come descritto nell’articolo precedente, abbiamo creato un ambiente virtuale dove abbiamo installato Matplotlib, Pandas e pandas-datareader. Se proviamo a importare pandas-datareader in un notebook nell’ambiente “base” di anaconda, otteniamo l’errore ModuleNotFoundError. Abbiamo questo errore perchè l’ambiente base di anaconda non ha accesso alle librerie installate nell’ambiente virtuale.
Configurazione di Jupyter Notebook con ipykernel
Per accedere alle librerie dell’ambiente virtuale tramite il notebook Jupyter in modo semplice possiamo usare ipykernel . Questo pacchetto è installato direttamente nell’ambiente virtuale e permette di scegliere il kernel relativo all’ambiente virtuale dall’interfaccia del notebook Jupyter. Diamo un’occhiata a uno dei modi più semplici per raggiungere questo obiettivo.
Iniziamo con il creare un ambiente virtuale e installare le librerie desiderate. Se hai seguito questa serie di articoli potresti semplicemente attivare l’ambiente py3.8 che abbiamo creato nell’articolo precedente. In caso contrario dobbiamo creare un ambiente virtuale e installare Matplotlib, Pandas e pandas-datareader.
(base)$ conda activate py3.8
Una volta all’interno dell’ambiente virtuale dobbiamo installare ipykernel
(py3.8)$ conda install ipykernel
Dobbiamo ora registrare le specifiche del kernel con Jupyter. Possiamo rinominare il kernel come preferiamo tramite il parametro –name=.
(py3.8)$ ipython kernel install --user --name=py3.8
Abbiamo un kernel funzionante per il nostro ambiente virtuale. Ora possiamo aprire il notebook Jupyter dall’ambiente base di anaconda e creare un nuovo notebook specificando il kernel appena creato. Nel nuovo notebook possiamo eseguire il comando import pandas_datareader.data as web senza ricevere errori. Apriamo una nuova finestra del terminale nell’ambiente base di anaconda (suggerimento: controllare che (base) sia visualizzata nella finestra di terminale prima delle informazioni sull’utente). Digitiamo quindi jupyter notebook per aprire jupyter nel browser. Una volta aperto, facciamo clic su Nuovo e selezioniamo il nuovo kernel dal menu a discesa.
Trading algoritmico con Jupyter
Iniziamo ricreando l’analisi descritta dell’articolo precedente. L’unica differenza è che in questo caso incorporiamo tutto in un notebook Jupyter dove possiamo salvare il lavoro e modificarlo nel tempo. Una panoramica completa dei comandi Jupyter non è lo scopo di questo articolo poiché ci concentriamo principalmente sull’analisi di serie temporali di dati finanziarie. Sono disponibili alcuni ottimi tutorial su dataquest e datacamp per scoprire tutto il potenziale del software. In sintesi i comandi più utilizzati sono:
enterper accedere alla modalità di modificaescper accedere alla modalità di comando- Una volta in modalità di comando (dopo aver premuto esc)
Mtrasforma una cella in Markdown in modo da poter aggiungere testoYtrasforma una cella in codiceAeBaggiunge una nuova cella sopra o sotto- tasti freccia
UpeDownper muoversi su e giù per le celle DDelimina la cellaHapre il menu delle scorciatoie da tastiera
Per creare un ambiente di ricerca e sviluppo di Trading algoritmico con Jupyter notebook iniziamo importando le librerie. Digitiamo il seguente codice nella prima cella e premiamo Maiusc+Invio. Il comando permette di eseguire la cella e crearne una nuova sottostante.
import matplotlib.pyplot as plt
import pandas as pd
import pandas_datareader.data as web
from datetime import datetime as dt
Ora definiamo l’intervallo di date e importiamo i dati:
aapl = web.DataReader("AAPl", "stooq")
Per visualizzare le prime righe del DataFrame usiamo il comando aapl.head().
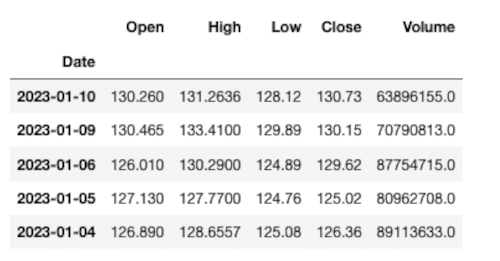
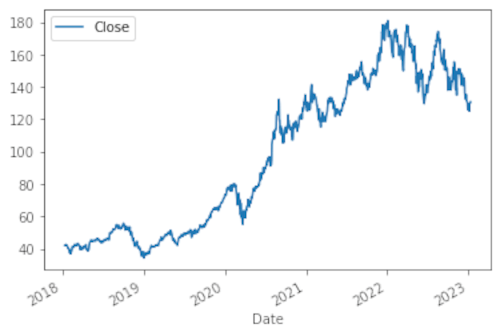
Possiamo visualizzare il grafico dei prezzi di chiusura scrivendo aapl.plot(y="Close") in una nuova cella e premendo MAIUSC+INVIO.
Grafici a candele giapponesi con Jupyter
Si ritiene che i grafici candlestick (candele giapponesi) risalgano al Giappone della fine del 1800. Una candela giapponese rappresenta l’oscillazione del prezzo nell’unità di tempo, che può andare dal singolo minuto fino ad un mese. E’ formata da un corpo centrale definito Real-Body (corpo reale), il quale indica l’escursione di prezzo tra l’apertura e la chiusura, e le Shadows (ombre), singole linee sottili che rappresentano i prezzi massimi e minimi del lasso di tempo prescelto, rispettivamente Upper Shadow (ombra superiore) e Lower Shadow (ombra inferiore). Come per il grafico a barre quindi sono necessari i valori di apertura, massimo, minimo e chiusura.
Il riempimento o il colore del corpo della candela rappresentano la variazione del prezzo durante il periodo di riferimento. Normalmente, se l’asset chiude più in alto rispetto all’apertura, il corpo viene visualizzato vuoto (o di colore verde). Al contrario, se l’asset ha chiuso a un livello inferiore rispetto a quello di apertura, il corpo viene visualizzato riempito (o di colore rosso).
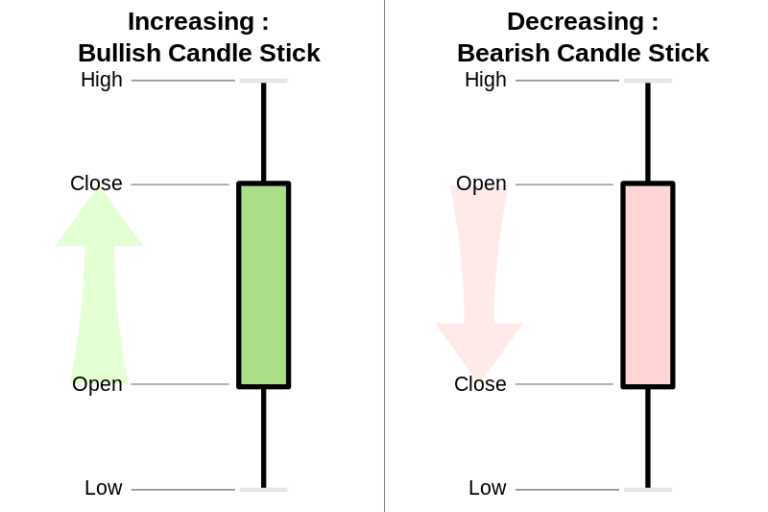
Esistono diversi modi per creare i grafici a candele con Python. Possiamo creare script che usano la funzione boxplot di Matplotlib, oppure altre librerie open source come mplfinance, bqplot, Bokeh e Plotly. In questo articolo utilizziamo Plotly per creare i grafici a candele.
La libreria Plotly
La libreria grafica Plotly di Python offre oltre 40 diversi tipi di grafici per usi statistici, finanziari, scientifici e tridimensionali. Le prime versioni di questa libreria richiedevano agli utenti di registrarsi per ottenere una chiave API da usare per accedere alla libreria ogni volta che creavano un grafico. C’era anche la possibilità di pubblicare le immagini in un archivio online di grafici scegliendo tra la modalità operativa online e offline. Dalla versione quattro del software non è più necessario avere un account o una connessione internet e non è richiesto alcun pagamento per utilizzare Plotly.py.
Al momento della scrittura l’ultima versione del software è la versione 5.6.0. Per poter utilizzare Plotly dobbiamo installarlo nell’ambiente virtuale. Nel terminale all’interno dello stesso ambiente virtuale che abbiamo utilizzato per creare il kernel, installiamo Plotly tramite conda.
(py3.8)$ conda install -c plotly plotly
Una volta completata l’installazione è necessario riavviare il kernel nel notebook Jupyter. Nel menu selezioniamo il Kernel, quindi “Riavvia ed Esegui tutto” nel menu a discesa. In questo modo possiamo eseguire nuovamente tutte le celle del notebook e aggiornare il kernel per includere l’accesso a Plotly.
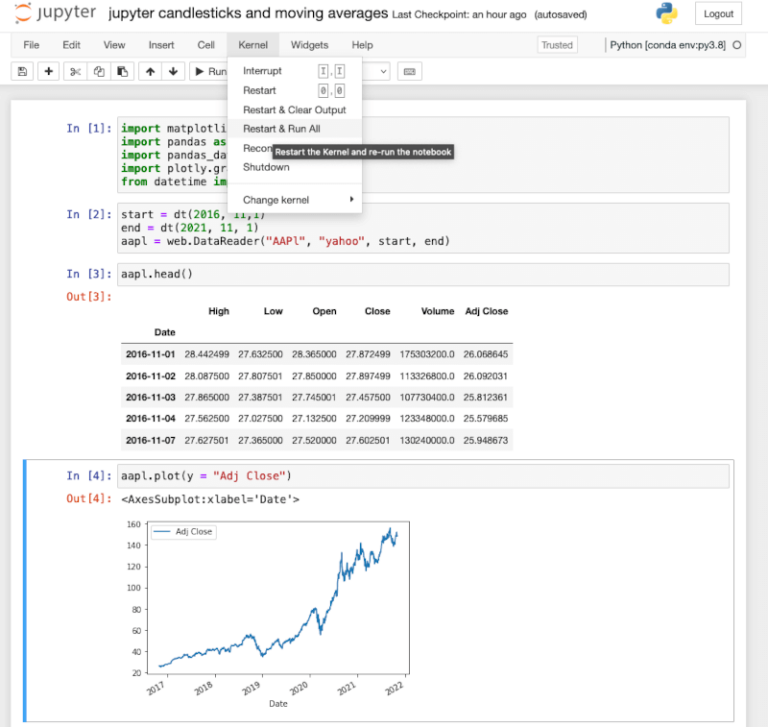
Importazione dei dati storici
Per semplificare le immagini iniziamo con l’analisi di un solo mese di dati OHLC. In una nuova cella del notebook inseriamo il seguente codice per creare un nuovo DataFrame con un mese di dati OHLC di Google scaricati da Stooq.
goog = web.DataReader("GOOG", "stooq")
Creiamo una vista dei dati di Google per il mese di ottobre 2021. La vista può essere usata per filtrare il DataFrame dei dati storici per qulle date tramite la funzione df.loc.
start = dt(2021, 10, 01)
end = dt(2021, 11, 01)
mask = (goog.index >= start) & (goog.index <= end)
goog = goog.loc[mask]
Possiamo controllare il DataFrame digitando goog.head(). Dobbiamo ora importare Plotly nel notebook. La migliore procedura consiste nel posizionare tutte le importazioni all’inizio del codice, in ordine alfabetico. Ciò garantisce che esaminando il codice è semplice vedere quali librerie sono state aggiunte e è facile determinare da dove ha avuto origine un metodo quando un metodo viene chiamato da una qualsiasi delle librerie,
Possiamo anche creare un alias per le importazioni come abbiamo fatto nel seguente esempio. In questo modo non è necessario digitare plotly.graph_objects ogni volta che vogliamo usare il metodo ma possiamo semplicemente digitare l’alias, in questo caso “go”. Aggiungiamo import plotly.graph_objects as go nella prima cella del notebook sotto l’importazione di pandas_datareader.
Plotly include le funzioni per creare un grafico a candele interattivo. Tutto quello che dobbiamo fare è definire i dati e chiamare la funzione. Per generare il grafico il metodo Candlestick richiede di specificare i dati dell’asse x, il prezzo di apertura, massimo, minimo e di chiusura. Aggiungiamo un nome al grafico in modo che il nome apparirà nella legenda se vogliamo aggiungere ulteriori elementi al grafico.
# definisce i dati
candlestick = go.Candlestick(
x=goog.index,
open=goog['Open'],
high=goog['High'],
low=goog['Low'],
close=goog['Close'],
name="OHLC"
)
# crea la figura
fig = go.Figure(data=[candlestick])
# visualizza il grafico
fig.show()
Il grafico prodotto è interattivo. Possiamo passare il mouse sopra una qualsiasi delle candele e vedere i relativi dati OHLC. Nella parte inferiore del grafico c’è un o slider che permette di selezionare l’intervallo di tempo, in questo modo è possibile ingrandire un o specifico intervallo di dati. Lo slider può essere disabilitato aggiungendo la seguente riga prima del comando fig.show(): fig.update_layout(xaxis_rangeslider_visible=False).
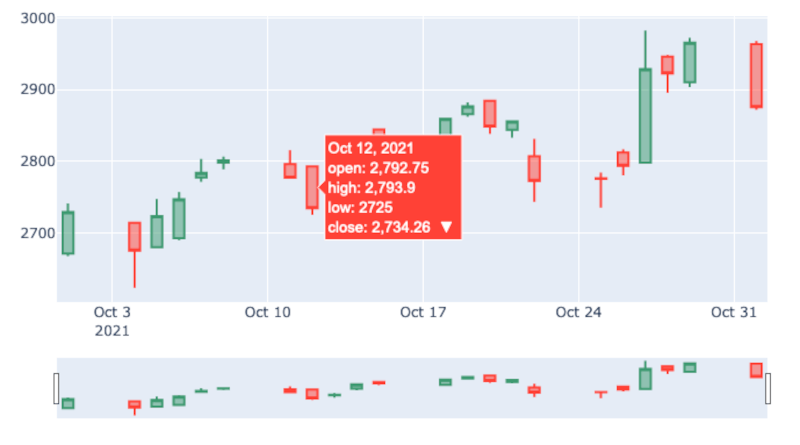
Aggiungere trendline ai grafici a candele con Plotly
Il metodo Figure() prevede la parola chiave data che accetta un elenco. In questo modo possiamo aggiungere trendline al grafico tramite la definizione di variabili aggiuntive contenenti il metodo Scatter. Vediamolo in azione inserendo una media mobile di cinque giorni al grafico a candele. Per iniziare dobbiamo calcolare la media mobile tramite i metodi rolling() e mean() di Pandas. In una nuova cella aggiungeremo ald Dataframe una serie contenente il valore della media mobile di cinque giorni per ogni punto temporale.
goog['MA5'] = goog.Close.rolling(5).mean()
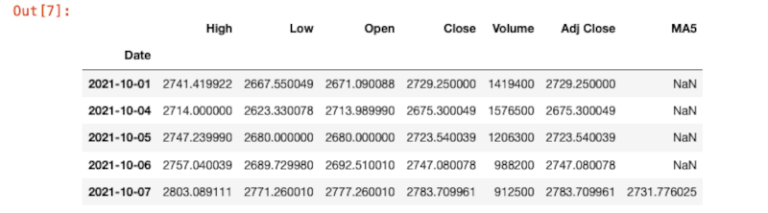
Il comando goog.head() mostra la nuova colonna con il primo valore calcolato nella quinta riga, come previsto.
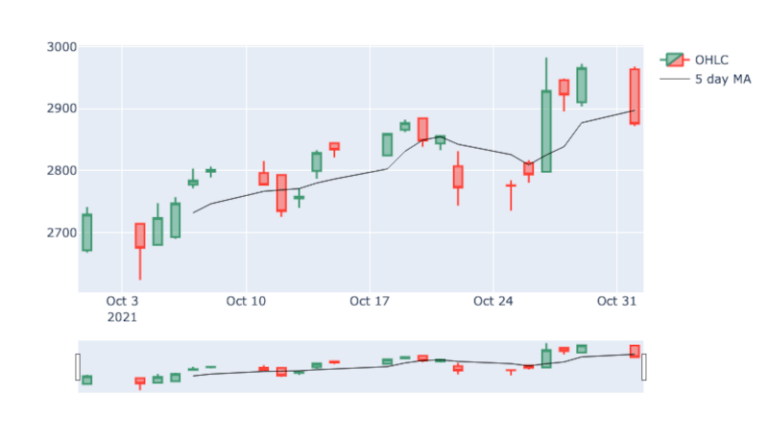
Ora possiamo creare l’oggetto scatter specificando i punti dati x e y. Possiamo creare una trendline anziché dei marcatori utilizzando la parola chiave line e controllando il colore e la larghezza della linea.
scatter = go.Scatter(
x=goog.index,
y=goog.MA5,
line=dict(color='black', width=1),
name="5 day MA"
)
Una volta definiti i dati, possiamo visualizzarli al grafico aggiungendo la variabile scatter all’elenco specificato nella parola chiave data.
fig = go.Figure(data=[candlestick, scatter])
fig.show()
Aggiungere i volume ai grafici a candele con Plotly
Per aggiungere i volumi al grafico a candele possiamo procedere in due modi; come sovrapposizione sul grafico esistente con un asse secondario o sotto il grafico a candele originale. Entrambe le opzioni richiedono l’utilizzo della classe make_subpplots di Plotly. La prima cosa che dobbiamo fare è importare la classe nella parte superiore del notebook. Per restare al passo con le migliori pratiche, dopo l’importazione di plotly.graph_objects aggiungi amo la seguente riga: from plotly.subplots import make_subplots.
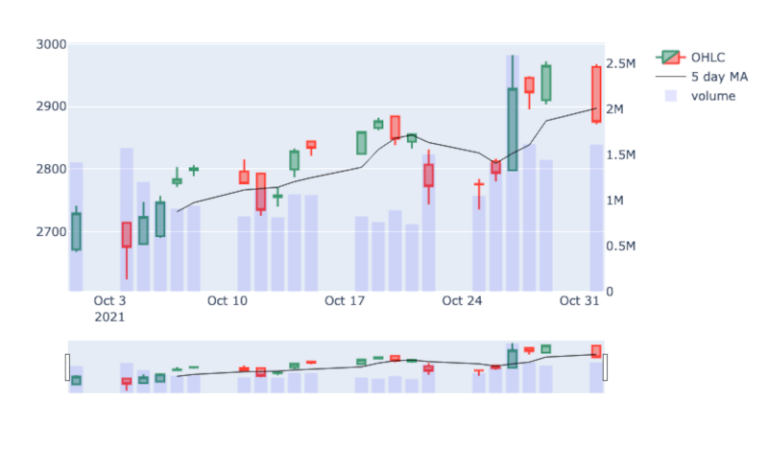
Ora possiamo creare un grafico con asse secondario per il volume. Per prima cosa creiamo l’asse secondario, quindi aggiungiamo una traccia per i dati OHLC delle candele e uno scatter per la media mobile di cinque giorni. Questo può essere fatto invocando le variabili candlestick e scatter che abbiamo creato in precedenza. Quindi aggiungiamo una traccia per un grafico a barre contenente i dati del volume. Possiamo controllare la trasparenza del grafico a barre con la parola chiave opacity e il colore usando la parola chiave marker_colour. Infine disattiviamo la griglia dell’asse secondario per evitare confusione nella visualizzazione del grafico finale.
# crea un grafico con un asse secondario
fig = make_subplots(specs=[[{"secondary_y": True}]])
fig.add_trace(
candlestick,
secondary_y=False
)
fig.add_trace(
scatter,
secondary_y=False
)
fig.add_trace(
go.Bar(x=goog.index, y=goog['Volume'], opacity=0.1, marker_color='blue', name="volume"),
secondary_y=True
)
fig.layout.yaxis2.showgrid=False
fig.show()
Se preferiamo visualizzare i volumi in un grafico separato, Plotly permette di farlo molto facilmente. Tutto quello che dobbiamo fare è aggiungere una trama nella chiamata al metodo make_subplots e definire la posizione di ciascuna traccia all’interno delle sottotrame. Iniziamo definendo la sottotrama utilizzando righe e colonne. In questo caso abbiamo bisogno una colonna e due righe per ottenere due grafici, uno sopra l’altro. I due grafici condividono l’asse x poiché le date delle serie temporali sono il fattore comune tra i due grafici.
Prevediamo uno spazio verticale aggiuntivo di 0,1 per inserire i titoli dei grafici. Infine specifichiamo altezza relativa delle righe, l’una rispetto all’altra. Il valore totale delle altezze delle righe verrà normalizzato in modo che la somma sia 1. Dopo aver definito i grafici aggiungiamo semplicemente ogni traccia come abbiamo fatto in precedenza specificando la posizione di ciascuna traccia all’interno delle sottotrame. Disabilitiamo quindi il cursore dell’intervallo per evitare confusione e visualizzare la cifra finale.
# Crea le sottotrame
fig = make_subplots(
rows=2, cols=1,
shared_xaxes=True,
vertical_spacing=0.1,
subplot_titles=('OHLC', 'Volume'),
row_heights=[0.7, 0.3]
)
# Grafico candlestick sulla 1° riga
fig.add_trace(
candlestick,
row=1, col=1
)
# Grafico scatter sulla 1° riga
fig.add_trace(
scatter,
row=1, col=1
)
# Grafico a barre dei volumi sulla 2° riga
fig.add_trace(
go.Bar(
x=goog.index,
y=goog['Volume'],
opacity=0.1,
marker_color='blue',
showlegend=False
),
row=2, col=1
)
# Non visualizza lo slider dell'intervallo temprale
fig.update(layout_xaxis_rangeslider_visible=False)
fig.show()
Prossimi passi
Facendo seguito alla serie di articoli sulla creazione di un framework con Python, questo articolo ha descritto un esempio di sviluppo del trading algoritmico Jupyter notebook e Plotly per produrre grafici a candele. Negli articoli successivi continueremo a descrivere altri esempi con Jupyter notebook per creare un ambiente di ricerca e prototipazione di strategie di trading algoritmico