Nella 1° Parte di questo articolo abbiamo descritto il modello autoregressivo di ordine p, noto anche come modello AR(p). Lo abbiamo introdotto come un’estensione del modello della random walk nel tentativo di spiegare una correlazione seriale aggiuntiva nelle serie temporali finanziarie.
Alla fine ci siamo resi conto che non era sufficientemente flessibile per catturare veramente tutta l’autocorrelazione delle serie temporali finanziarie. La ragione principale di ciò è che gli asset finanziari sono condizionalmente eteroschedastici, cioè non sono stazionari e hanno periodi di “varianza variabile” o clustering di volatilità, che non viene preso in considerazione dal modello AR(p).
Nei prossimi articoli descriviamo i modelli ARIMA (Autoregressive Integrated Moving Average), così come i modelli condizionalmente eteroschedastici delle famiglie ARCH e GARCH. Questi modelli ci forniranno i primi tentativi realistici di prevedere i prezzi degli asset.
In questo articolo, tuttavia, introdurremo il modello della media mobile di ordine q, noto come MA(q). Questo è un componente del più generico modello ARMA e come tale dobbiamo capirlo prima di andare oltre.
Ti consiglio vivamente di leggere gli articoli precedenti nella raccolta Time Series Analysis se non l’hai già fatto. Si possono trovare tutti qui.
Modelli a Media Mobile (MA) di ordine q
Fondamento logico
Un modello a media mobile è simile a un modello autoregressivo, tranne per il fatto che invece di essere una combinazione lineare di valori passati delle serie temporali, è una combinazione lineare dei termini passati di rumore bianco. Intuitivamente, ciò significa che il modello MA vede tali casuali “shock” di rumore bianco direttamente per ciascun valore corrente del modello. Ciò è in contrasto con un modello AR(p), in cui gli “shock” del rumore bianco sono visti solo indirettamente, tramite la regressione ai precedenti termini della serie. Una differenza fondamentale è che il modello MA considera sempre e solo l’ultimo shock “q” per ogni particolare modello MA(q), mentre il modello AR(p) considera di tutti gli shock precedenti, anche se in maniera decrescente.Definizione
Matematicamente, il MA(q) è un modello di regressione lineare ed è strutturato in modo simile al AR(p):Modello a media mobile dell’ordine q Un modello di serie storica, \(\{x_t\}\), è un modello a media mobile di ordine q, MA(q), se:Utilizzeremo la \(\phi\) funzione negli articoli successivi.\(\begin{eqnarray}x_t = w_t + \beta_1 w_{t-1} + \ldots + \beta_q w_{t-q}\end{eqnarray}\)
Dove \(\{ w_t \}\) è il rumore bianco con \(E(w_t) = 0\) e varianza \(\sigma^2\). Se consideriamo l’operatore di spostamento all’indietro, B (vedi un articolo precedente) allora possiamo riscrivere quanto sopra come una funzione \(\phi\) di B:\(\begin{eqnarray} x_t = (1 + \beta_1 {\bf B} + \beta_2 {\bf B}^2 + \ldots + \beta_q {\bf B}^q) w_t = \phi_q ({\bf B}) w_t \end{eqnarray}\)
Proprietà del secondo ordine
Come per AR(p), la media di un processo MA(q) è zero. Questo è facile da vedere poiché la media è semplicemente la somma delle medie dei termini del rumore bianco, che sono a loro volta tutti pari a zero.\(\begin{eqnarray}\text{Media:} \enspace \mu_x = E(x_t) = \sum^{q}_{i=0} E(w_i) = 0 \end{eqnarray}\)
\(\begin{eqnarray} \text{Varianza:} \enspace \sigma^2_w (1 + \beta^2_1 + \ldots + \beta^2_q) \end{eqnarray}\)
\(\text{ACF:} \enspace \rho_k = \left\{\begin{aligned} &1 && \text{if} \enspace k = 0 \\ &\sum^{q-k}_{i=0} \beta_i \beta_{i+k} / \sum^q_{i=0} \beta^2_i && \text{if} \enspace k = 1, \ldots, q \\ &0 && \text{if} \enspace k > q \end{aligned} \right.\)
Dove \(\beta_0 = 1\) Ora generiamo alcuni dati simulati e li usiamoper creare correlogrammi. Questo renderà la formula sopra per un po’ più concreta.Simulazioni e Correlogrammi
MA(1)
Iniziamo con un processo MA(1). Se consideriamo \(\beta_1 = 0.6\) si ha il seguente modello:
\(\begin{eqnarray} x_t = w_t + 0.6 w_{t-1} \end{eqnarray}\)
In modo analogo ai modelli AR(p) descritti nell’articolo precedente, possiamo usare la libreria Statsmodels di Python per simulare tale serie e quindi tracciare il correlogramma. Dato che abbiamo descritto questo approccio nella precedente serie di articoli sull’analisi delle serie temporali per la visualizzazione dei grafici, riportiamo l’intero codice, anziché dividerlo:
# MA parameter = +0.6
ar1 = np.array([1])
ma1 = np.array([1, 0.6])
MA_object1 = ArmaProcess(ar1, ma1)
simulated_data_1 = MA_object1.generate_sample(nsample=100)
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
# Plot MA model
plt.plot(simulated_data_1)
plot_acf(simulated_data_1, alpha=1, lags=20);
plt.show()
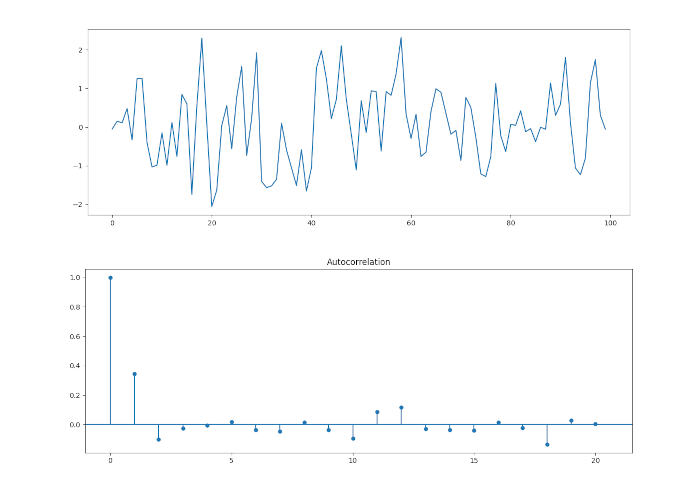
Come descritto in precedenza nella formula di \(\rho_k\), per \(k > q\), tutte le autocorrelazioni dovrebbero essere zero. Con \(q = 1\), dovremmo vedere un picco significativo a \(k=1\) e poi picchi successivi poco significativi. Tuttavia, a causa della distorsione del campionamento, dovremmo aspettarci di vedere picchi (marginalmente) significativi del 5% su un grafico di autocorrelazione del campione.
Questo è esattamente ciò che il correlogramma ci mostra in questo caso. Abbiamo un picco significativo per \(k=1\) e poi picchi insignificanti per \(k>1\).
In effetti, questo è un modo utile per vedere se un modello MA(q) è appropriato. Dando un’occhiata al correlogramma di una particolare serie possiamo vedere quanti ritardi sequenziali diversi da zero esistono. Se esistono tali ritardi possiamo legittimamente tentare di adattare un modello MA(q) a una particolare serie.
Poiché disponiamo di prove dai nostri dati simulati di un processo MA(1), possiamo provare a adattare un modello MA(1) ai nostri dati simulati.
Per dati simulati con \(\beta=0.6\), con la funzione ARMA della libreria statsmodels possiamo calcolare il valore stimato di \(\beta\). Inoltre possiamo stampare l’intero report che viene prodotto quando si adatta una serie temporale, in modo da poter avere un’idea di quali altri test e statistiche riassuntive sono disponibili in statsmodels.
from statsmodels.tsa.arima_model import ARMA
# Fit an MA(1) model to the first simulated data
mod = ARMA(simulated_data_1, order=(0, 1))
res = mod.fit()
# Print out summary information on the fit
print(res.summary())
# Print out the estimate for the constant and for theta
print("When the true beta=0.6, the estimate of beta (and the constant) are:")
print(res.params)
ARMA Model Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: ARMA(0, 1) Log Likelihood -122.312
Method: css-mle S.D. of innovations 0.820
Date: 1 Oct 2017 AIC 250.624
Time: 11:27:50 BIC 258.440
Sample: 0 HQIC 253.787
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0813 0.134 0.607 0.545 -0.181 0.344
ma.L1.y 0.6394 0.082 7.819 0.000 0.479 0.800
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
MA.1 -1.5639 +0.0000j 1.5639 0.5000
-----------------------------------------------------------------------------
When the true beta=0.6, the estimate of beta (and the constant) are:
[0.08131956 0.63942772]
Il report prodotto dalla funzione ARMA contiene molte informazioni utili. In primo luogo, possiamo vedere che il parametro è stato stimato come \(\hat{\beta_1} = 0.639\), che è molto vicino al valore reale di \(\hat{\beta_1} = 0.6\). In secondo luogo, gli errori standard sono già calcolati per noi, rendendo semplice il calcolo degli intervalli di confidenza. In terzo luogo, riceviamo una varianza stimata, una probabilità logaritmica e un criterio di informazione Akaike (necessario per il confronto del modello).
Possiamo vedere che l’intervallo di confidenza al 95% contiene il valore del parametro vero
e quindi possiamo giudicare il modello adatto. Ovviamente questo corrisponde a quanto previsto poiché abbiamo simulato i dati di partenza!
MA(1) con parametro negativo
Come cambiano le cose se modifichiamo il segno di \({\beta_1}\) a -0,6? Eseguiamo la stessa analisi:
# MA parameter = -0.6
ar1 = np.array([1])
ma1 = np.array([1, -0.6])
MA_object1 = ArmaProcess(ar1, ma1)
simulated_data_1 = MA_object1.generate_sample(nsample=100)
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
# Plot MA model
plt.plot(simulated_data_1)
plot_acf(simulated_data_1, alpha=1, lags=20)
plt.show()
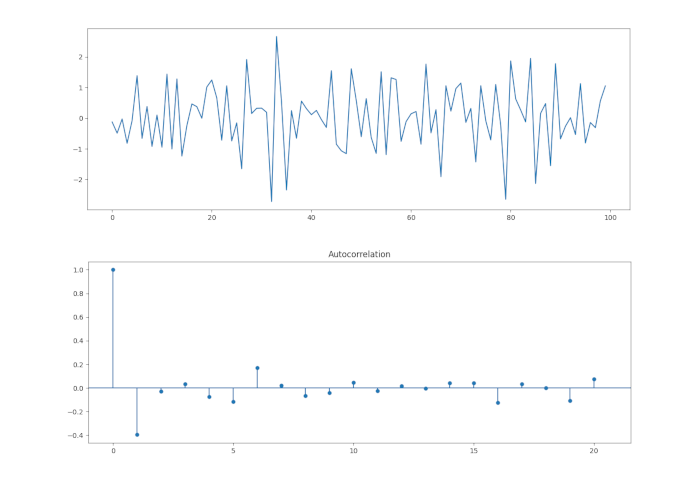
Da notare che per k=1 abbiamo un picco significativo nel correlogramma, che mostra una correlazione negativa, come ci si aspetterebbe da un modello MA(1) con primo coefficiente negativo. Ancora una volta tutti i picchi successivi a K=1 non sono significativi.
Come in precedenza, ora adattiamo un modello MA(1) e stimiamo il parametro tramite la funzione ARMA:
from statsmodels.tsa.arima_model import ARMA
# Fit an MA(1) model to the first simulated data
mod = ARMA(simulated_data_1, order=(0, 1))
res = mod.fit()
# Print out summary information on the fit
print(res.summary())
# Print out the estimate for the constant and for theta
print("When the true beta=-0.6, the estimate of beta (and the constant) are:")
print(res.params)
ARMA Model Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: ARMA(0, 1) Log Likelihood -138.684
Method: css-mle S.D. of innovations 0.966
Date: 1 Oct 2017 AIC 283.367
Time: 12:20:50 BIC 291.183
Sample: 0 HQIC 286.530
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 0.1202 0.038 3.201 0.002 0.047 0.194
ma.L1.y -0.6177 0.073 -8.437 0.000 -0.761 -0.474
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
MA.1 1.6190 +0.0000j 1.6190 0.0000
-----------------------------------------------------------------------------
When the true beta=-0.6, the estimate of beta (and the constant) are:
[ 0.12021088 -0.61767038]
Possiamo vedere che il parametro stimato \(\beta_1 = -0.617\) è leggermente inferiore al valore del vero parametro \(\beta_1 = -0.6\).
Inoltre vediamo che \(\beta_1 = -0.6\) è contenuto all’interno dell’intervallo di confidenza del 95%, fornendoci la prova di un buon adattamento del modello.
MA(3)
Eseguiamo la stessa procedura per un processo MA(3). Questa volta dovremmo aspettarci picchi significativi per \(k \in \{1,2,3 \}\), e picchi insignificanti per \(k > 3\).
Utilizzeremo i seguenti coefficienti: \(\beta_1 = 0.6\), \(\beta_1 = 0.4\) e \(\beta_1 = 0.2\). Simuliamo un processo MA(3) di questo modello. Per questa simulazione abbiamo aumentato il numero di campioni casuali a 1000, il che rende più facile vedere la vera struttura di autocorrelazione, a scapito di rendere più difficile interpretare la serie originale:
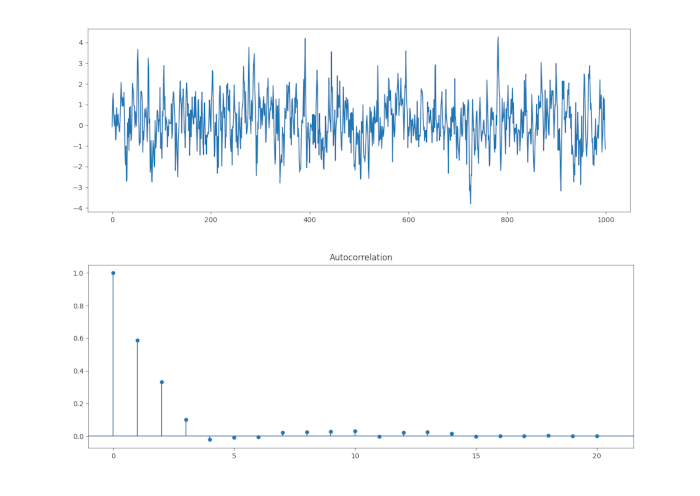
Come previsto, i primi tre picchi sono significativi. Tuttavia, lo è anche il quarto. Ma possiamo legittimamente suggerire che ciò potrebbe essere dovuto ad un bias di campionamento poiché prevediamo che il 5% dei picchi sia significativo oltre \(k=q\).
Adattiamo ora un modello MA(3) ai dati per provare a stimare i parametri:
from statsmodels.tsa.arima_model import ARMA
# Fit an MA(1) model to the first simulated data
mod = ARMA(simulated_data_1, order=(0, 3))
res = mod.fit()
# Print out summary information on the fit
print(res.summary())
# Print out the estimate for the constant and for theta
print("When the true beta={0.6, 0.4, 0.2} and the estimate of beta (and the constant) are:")
print(res.params)
ARMA Model Results
==============================================================================
Dep. Variable: y No. Observations: 1000
Model: ARMA(0, 3) Log Likelihood -1437.030
Method: css-mle S.D. of innovations 1.018
Date: 01 Oct 2017 AIC 2884.059
Time: 12:45:19 BIC 2908.598
Sample: 0 HQIC 2893.386
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -0.0671 0.072 -0.928 0.354 -0.209 0.075
ma.L1.y 0.6265 0.031 20.250 0.000 0.566 0.687
ma.L2.y 0.4302 0.035 12.160 0.000 0.361 0.499
ma.L3.y 0.1911 0.031 6.223 0.000 0.131 0.251
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
MA.1 -0.1519 -1.6323j 1.6393 -0.2648
MA.2 -0.1519 +1.6323j 1.6393 0.2648
MA.3 -1.9475 -0.0000j 1.9475 -0.5000
-----------------------------------------------------------------------------
When the true beta={0.6, 0.4, 0.2} and the estimate of beta (and the constant) are:
[-0.06708383 0.62654906 0.43016213 0.19107343]
Process finished with exit code 0
Prossimi Passi
Abbiamo esaminato in dettaglio i due principali modelli di serie temporali, vale a dire il modello autogressivo dell’ordine p, AR(p) e poi la media mobile dell’ordine q, MA(q). Abbiamo visto che entrambi sono in grado di spiegare parte dell’autocorrelazione, ma non riescono a modellare il clustering di volatilità e gli effetti a memoria lunga.
È finalmente giunto il momento di rivolgere la nostra attenzione alla combinazione di questi due modelli, ovvero la Media Mobile Autoregressiva di ordine p e q, ARMA(p,q) per vedere se migliorerà ulteriormente la situazione.
Tuttavia, dovremo aspettare fino al prossimo articolo per una discussione completa!