
La finanza quantitativa è un settore estremamente competitivo a livello istituzionale. Gli hedge fund quantistici competono per grandi allocazioni e devono continuamente dimostrare il loro valore per ricevere nuovi asset in gestione. Ciò determina un notevole sforzo di ricerca e sviluppo per ottenere nuove fonti di rendimenti non correlati, corretti per il rischio, per i propri clienti. I fondi e i loro trading desk devono continuamente cercare nuove fonti di alpha. Questo a volte può essere trovato in nuovi mercati, con fonti di dati innovative o con migliori algoritmi predittivi.
Negli ultimi anni gran parte del settore degli hedge fund quantitativi ha rivolto la propria attenzione ai cosiddetti dati alternativi come mezzo per generare nuovi alpha. Tali dati sono spesso in formati non strutturati, inadatti ai tradizionali approcci di modellazione basati sulle serie temporali. C’è una forte spinta a sfruttare i meccanismi in grado di estrarre valore da questi set di dati e utilizzarli per la generazione di segnali predittivi. Uno di questi campi che ha attirato molta attenzione negli ultimi anni è quello del deep learning .
Per saperne di più sul deep learning, possiamo leggere l’articolo precedente: Che cos’è il deep learning?
Anche il deep learning non è sfuggito all’attenzione del trader retail. L’ascesa esponenziale di potenti software open source, insieme alla disponibilità sempre crescente di dati, combinata con l’accesso a hardware molto potente a basso costo ha portato molti trader retails a perseguire strategie di trading basate su modelli di deep learning.
Nonostante la relativa semplicità delle API fornite dai moderni framework di deep learning, c’è ancora una notevole curva di apprendimento da superare per poter svolgere con successo ricerche di trading quantitativo usando gli approcci di deep learning.
Introduzione
Come con qualsiasi modello predittivo complesso, non è sufficiente “copiare e incollare” il codice del modello open source e sperare di generare una solida strategia di trading. È invece necessaria una buona comprensione dei modelli sottostanti per evitare insidie comuni come l’overfitting.
In questa nuova serie di articoli esploriamo i modelli di deep learning, studiando la teoria dei modelli comuni e successivamente descrivendo solide implementazioni che possono essere usate ed estese per i propri scopi di trading.
È comune per molti tutorial di deep learning passare direttamente al codice. Sebbene questo sia un approccio di apprendimento utile per esempi relativamente semplici, come la classificazione di oggetti nelle immagini, è meno appropriato nel regno della finanza quantitativa, dove gli errori del modello possono portare a una non redditività significativa.
Per questo motivo in DataTrading enfatizziamo sia la teoria che la pratica al fine di fornire una comprensione dell’argomento a tutto tondo e per aiutare a mitigare le perdite di trading causate da implementazioni di modelli mal costruiti.
Questo articolo inizia introducendo i modelli di rete neurale artificiale (ANN). Descrive come sono ispirati dalle reti neurali biologiche. L’attenzione si sposta quindi su uno dei primi modelli di rete neurale, noto come perceptron .
Negli articoli futuri usiamo il modello percettronico come un ‘blocco costitutivo’ verso la costruzione di reti neurali profonde più sofisticate come i percettron multistrato (MLP), dimostrando il loro potere su alcuni problemi di deep learning non banali.
Reti neurali artificiali
Il deep learning può sembrare un campo estremamente moderno, ma la ricerca in quest’area è iniziata negli anni ’40. Più o meno allo stesso modo in cui gli uccelli hanno sempre motivato gli esseri umani a sviluppare un volo più pesante dell’aria, l’architettura del cervello umano ha motivato gli esseri umani a provare a replicare l’intelligenza attraverso simili strutture neurali.
Lo stesso neurone ha fornito l’ispirazione per lo sviluppo di reti di neuroni computazionali, che possono essere combinate per produrre calcoli sofisticati a partire da architetture di rete abbastanza semplici.
La disposizione della corteccia cerebrale umana è stata anche una motivazione significativa in alcune architetture di reti neurali profonde come la Convolutional Neural Network (CNN), che sarà al oggetti di articoli successivi.
La ricerca sulle reti di neuroni computazionali o reti neurali artificiali è stata caratterizzata da periodi di intenso sviluppo e finanziamento insieme a periodi relativamente dormienti noti come “Inverni AI” in cui le promesse di tale tecnologia spesso non sono mai state all’altezza dell’attuale clamore.
In parte ciò può essere attribuito a modelli non sufficientemente complessi che erano difficili da addestrare in un lasso di tempo ragionevole. Un altro fattore che ha contribuito è stato il costo per ottenere, archiviare ed elaborare le grandi quantità di dati necessari per ottenere buoni risultati.
Negli ultimi anni le sfide di cui sopra sono state ampiamente superate. Ciò ha determinato una crescita esplosiva nella ricerca sull’ANN. L’avvento della Graphics Processing Unit (GPU) ha fornito il meccanismo per una addestramento a basso costo. L’ascesa di Internet ha portato a quantità sbalorditive di dati facilmente disponibili. Gli algoritmi di addestramento sono migliorati costantemente, così come le architetture dei modelli.
La confluenza di questi fattori ha prodotto risultati all’avanguardia su molti problemi complessi mediante modelli di deep learning, precedentemente considerati intrattabili.
Sebbene la storia della ricerca sulle reti neurali artificiali sia un argomento affascinante di per sé, l’obiettivo di questo articolo è utilizzare questi strumenti come i professionisti del trading quantitativo in modo da generare rendimenti superiori ad un rischi adeguato. La storia delle rete neurali artificiali non rientra nell’ambito di questo articolo.
Per coloro che desiderano approfondire gli sviluppi storici delle reti neurali artificiali, consultare la sezione Tendenze storiche nell’apprendimento profondo all’interno del libro Deep Learning[1].
Inizieremo descrivendo uno dei modelli ANN più semplici possibili noto come perceptron.
Il Perceptron
In questo paragrafo introduciamo il perceptron[2]. È uno dei primi e più elementari modelli di rete neurale artificiale. Il perceptron è estremamente semplice per i moderni standard dei modelli di deep learning. Tuttavia, i concetti utilizzati nella sua progettazione si applicano in modo più ampio a sofisticate architetture di deep learning.
Il perceptron è un algoritmo di classificazione binaria di apprendimento supervisionato, originariamente sviluppato da Frank Rosenblatt nel 1957. Classifica i dati di input in uno di due stati separati sulla base di una procedura di addestramento eseguita su dati di input precedenti.
Il perceptron tenta di partizionare i dati di input tramite un confine di decisione lineare. Una procedura simile viene eseguita da un altro algoritmo di apprendimento supervisionato noto come classificatori di vettori di supporto, come descritto in un articolo precedente.
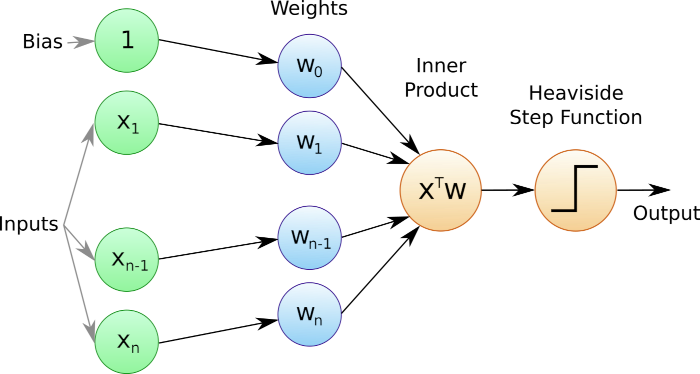
Il perceptron considera una serie di features scalari in input, insieme a un termine costante di “bias” e assegna pesi a questi input. Calcola poi una combinazione lineare dei pesi e degli input. Questa combinazione lineare viene poi alimentata attraverso una funzione di attivazione che determina a quale stato (o classe) appartiene l’insieme di input.
Funzioni di attivazione per il Perceptron
Nel caso del modello perceptron la funzione di attivazione scelta è una funzione gradino che restituisce uno di due valori distinti (tre nel caso della funzione Segno) a seconda del valore della combinazione lineare.
Le scelte comuni per la funzione passo nei percettron sono la funzione Heaviside e la funzione Segno .
La funzione Heaviside (dal nome di Oliver Heaviside ) è riportata di seguito:
\(\begin{eqnarray}h(z) = \begin{cases}
0 & \text{if $z < 0$} \\
1 & \text{if $z \geq 0$}
\end{cases}\end{eqnarray}\)
La funzione restituisce 0 se la combinazione lineare scelta z è minore di 0, altrimenti restituisce 1.
La funzione Segno è data di seguito:
\(\begin{eqnarray}\text{sgn}(z) = \begin{cases}
-1 & \text{if $z < 0$} \\ 0 & \text{if $z = 0$} \\ 1 & \text{if $z > 0$}
\end{cases}\end{eqnarray}\)
Cioè si restituisce -1 se la combinazione lineare scelta z è minore di 0, restituisce 0 se è 0, altrimenti restituisce +1.
Algoritmo per il Perceptron
La procedura matematica per determinare l’etichetta di classe di un insieme di dati di input è la seguente:
- Per un vettore di input x, con componenti dati da \(x_i\) dove \(i \in \{1,\ldots,n\}\), si considera il prodotto scalare di x e il vettore dei pesi w per calcolare la somma ponderata \({\bf x}^T {\bf w}\) degli input.
- Aggiungere il termine di distorsione b, a questa somma ponderata per calcolare \(z = {\bf x}^T {\bf w} + b\).
- Applicare l’appropriata funzione gradino per determinare l’etichetta di classe degli input.
L’algoritmo per il perceptron, quando si utilizza la funzione di attivazione di Heaviside, è riassunto nella seguente funzione:
\(\begin{eqnarray}
f(z) = \begin{cases}
1 & \text{if ${\bf x}^T {\bf w} + b > 0$} \\
0 & \text{otherwise}
\end{cases}
\end{eqnarray}\)
cioè la somma pesata degli input (incluso il bias) supera lo zero, classificare l’input con l’etichetta di stato 1, altrimenti classificarlo con l’etichetta di stato 0.
D notare che in alcuni manuale si aggiunge il termine bias al vettore dei pesi w aggiungendo un componente\(w_0\). A tale scopo è necessario aggiungere un componente \(x_0\) al vettore di input, che è sempre impostato su uno:\(x_0=1\). È quindi possibile scrivere l’algoritmo come:
\(\begin{eqnarray}
f(z) = \begin{cases}
1 & \text{if ${\bf x}^T {\bf w} > 0$} \\
0 & \text{otherwise}
\end{cases}
\end{eqnarray}\)
Sebbene questa notazione sia certamente più precisa, va sempre tenuto presente che un implicito termine di bias esiste come uno dei componenti di questa somma pesata.
Perché abbiamo bisogno di un termine bias?
A questo punto potrebbe valere la pena chiedersi perché è necessario un termine bias? Geometricamente è possibile pensare al confine lineare di decisione come a una linea (o iperpiano) che divide una regione in due sottoregioni separate che si escludono a vicenda.
Se non fosse presente un termine bias, questa linea (o iperpiano) sarebbe forzata a intersecare l’origine della regione. Ciò potrebbe ridurre significativamente le sue prestazioni predittive (o addirittura renderle inutili) se il “vero” confine decisionale non si trovasse sull’origine. Quindi è sempre necessario includere un termine bias per tenere conto di questa possibilità.
Prossimi passi
Sebbene l’algoritmo di classificazione di cui sopra fornisca una procedura chiara su come classificare i dati di input, non fornisce alcuna panoramica su come impostare i pesi (o bias) per consentire la corretta esecuzione dell’algoritmo.
Il prossimo articolo della serie discuterà come i percettroni vengono addestrati in modo da determinare un insieme ottimale di pesi e distorsioni da utilizzare nella classificazione lineare.
Una volta delineata la procedura di addestramento, inizieremo a “impilare” i percettron insieme per formare percettron multistrato che possono essere utilizzati per problemi di regressione e classificazione.
Riferimenti
- [1] Goodfellow, I.J., Bengio, Y., Courville, A. (2016) Deep Learning, MIT Press
- [2] Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65, 386-408.
- [3] Géron, A. (2019) Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Ed., O’Reilly Media
- [4] Krizhevsky, A., Sutskever, I., Hinton, G. (2012) “ImageNet Classification with Deep Convolutional Neural Networks”, Advances in Neural Information Processing Systems 25 (NIPS 2012)







