I questo articolo descriviamo come gestire gli split e i dividendi con Backtrader per analizzare i dati finanziari e costruire strategie di trading algoritmico.
Nel mercato azionario i dividendi sono un aspetto molto importante delle redditività dei trader ed investitori, tuttavia il loro impatto è spesso trascurato nei backtest retrospettivi. Questo può portarci ad abbandonare strategie redditizie e stimare erroneamente i rendimenti attesi di una strategia. In questo articolo vediamo l’importanza di contabilizzare e gestire i dividendi durante il backtesting e descriviamo come come scaricare e lavorare con i corretti dati in Backtrader.
Prerequisiti
Il seguente codice prevede di scaricare i dati storici delle serie finanziare da Alpha Vantage. A tale scopo è necessaria una chiave API gratuita. Pertanto, dobbiamo collegarci alla loro home page, registrarsi e creare una chiave API. L’API è gratuita ma ha un limite di circa 5 chiamate API al minuto. Oltre ad Alpha Vantage, usiamo un paio di moduli Python aggiuntivi che semplificano il lavoro. Questi moduli sono:
pandas: https://pandas.pydata.org/numpy: http://www.numpy.org/
Nota: per capire come installare i moduli Python, è possibile leggere l’articolo di Setup di base per Python e BackTrader o dalla documentazione ufficiale .
Gestire gli split e i dividendi con Backtrader
Il processo non è così semplice come scaricare i dati da un provider di dati. Se vogliamo usare i valori OHLCV, dobbiamo anche adattare alcune parti del codice. Pertanto, nel corso di questo articolo descriviamo quanto segue:
- Download di dati da Alpha Vantage
- Adeguamento dei dati
open,highelow. - Creazione di un feed di dati in Backtrader con
PandasData - Confronto dei rendimenti aggiustati e non aggiustati
Codice
from alpha_vantage.timeseries import TimeSeries
import backtrader as bt
from datetime import datetime
import argparse
import pandas as pd
import numpy as np
def parse_args():
parser = argparse.ArgumentParser(description='Market Data Downloader')
parser.add_argument('-s','--symbol',
type=str,
required=True,
help='The Symbol of the Instrument/Currency Pair To Download')
parser.add_argument('--adjusted',
action='store_true',
help='Use Adjusted Data')
parser.add_argument('--rounding',
default=4,
help='Round adjusted data to nearest x')
return parser.parse_args()
class testStrategy(bt.Strategy):
def next(self):
if not self.position:
self.order_target_percent(target=1)
def adjust(date, close, adj_close, in_col, rounding=4):
'''
Se uso forex o Crypto - Cambia l'arrotondamento!
'''
try:
factor = adj_close / close
return round(in_col * factor, rounding)
except ZeroDivisionError:
print('WARNING: DIRTY DATA >> {} Close: {} | Adj Close {} | in_col: {}'.format(date, close, adj_close, in_col))
return 0
args = parse_args()
apikey = 'INSERT YOUR API KEY'
# capitale iniziale
startcash = 10000
# creazione istanza di cerebro
cerebro = bt.Cerebro()
# aggiungere la strategia
cerebro.addstrategy(testStrategy)
# Download dei dati di Apple da ALPHA Vantage.
# -------------------------------
# Invio della API e creazione della sessione
alpha_ts = TimeSeries(key=apikey, output_format='pandas')
# Ottenre i dati
if args.adjusted:
data, meta_data = alpha_ts.get_daily_adjusted(symbol=args.symbol, outputsize='full')
# Conversione dell'indice in datetime.
data.index = pd.to_datetime(data.index)
# NOTA: Pandas Keys = '1. open', '2. high', '3. low', '4. close', '5. adjusted close',
# '6. volume','7. dividend', '8. split coefficient'
# Aggiustamento del resto dei dati
data['adj open'] = np.vectorize(adjust)(data.index.date, data['4. close'], data['5. adjusted close'], data['1. open'], rounding=args.rounding)
data['adj high'] = np.vectorize(adjust)(data.index.date, data['4. close'], data['5. adjusted close'], data['2. high'], rounding=args.rounding)
data['adj low'] = np.vectorize(adjust)(data.index.date, data['4. close'], data['5. adjusted close'], data['3. low'], rounding=args.rounding)
# Estrazione e Rinomina delle colonne con cui vogliamo lavoare
data = data[['adj open', 'adj high', 'adj low','5. adjusted close','6. volume']]
data.columns = ['Open','High','Low','Close','Volume']
else:
data, meta_data = alpha_ts.get_daily(symbol=args.symbol, outputsize='full')
# Conversione dell'indice in datetime.
data.index = pd.to_datetime(data.index)
# Rinomina le colonne
data.columns = ['Open','High','Low','Close','Volume']
# Aggiungere i dati a cerebro
data_in = bt.feeds.PandasData(dataname=data, timeframe=bt.TimeFrame.Days, compression=1)
cerebro.adddata(data_in)
# Impostazione del capitale iniziale
cerebro.broker.setcash(startcash)
# Esecuzione del backtest
cerebro.run()
# Ottenere il valore finale del portafoglio
portvalue = round(cerebro.broker.getvalue(),2)
pnl = portvalue - startcash
# Stampa del risultato finale
print('Final Portfolio Value: ${}'.format(portvalue))
print('P/L: ${}'.format(pnl))
# Grafico dei risultati
cerebro.plot(style='candlestick')
Commento al codice
Nello script per gestire gli split e i dividendi con Backtrader dobbiamo inserire una specifica chiave API. In particolare dobbiamo modificare la variabile apikey = 'INSERT YOUR API KEY'. Inoltre per poter confrontare facilmente i rendimenti aggiustati e non aggiustati, il codice permette di impostare gli argomenti in fase di esecuzione (run-time) tramite il modulo argparse. Per i neofiti che vogliono approfondire i concetti alla base del modulo argparse possono leggere il precedente articolo sulla gestione del modulo argparse con backtrader.
La strategia di test implementata nel codice è un semplice Buy & Hold. Da notare che nel codice non usiamo un semplice self.buy() ma usiamo la funzione order_target_percent che ci permette di provare a entrare in posizione con il x% del capitale. Per ulteriori dettagli sugli ordini target sono descritti nell’articolo “ordini target e stop loss con backtrader” .
Acquisizione dei dati
Successivamente, passiamo a qualcosa di un po’ più complicato. Dobbiamo scaricare, modificare e inserire i dati in Backtrader. Innanzitutto, scarichiamo i dati tramite il modulo alpha_vantage. I dati restituisti da Alpha Vantage sono all’interno di un dataframe di pandas. Se stampiamo il contenuto del dataframe con il metodo print() otteniamo un output simile al seguente:
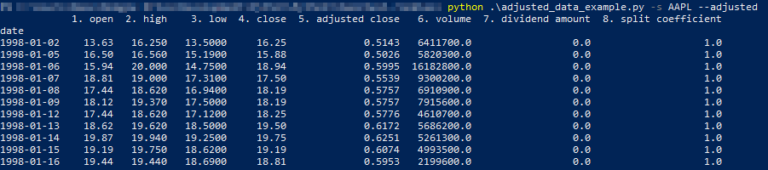
Come possiamo vedere, Alpha Vantage restuisce il valore aggiustato solamente per il prezzo di chiusura. Se vogliamo lavorare con i dati OHLC, dobbiamo apportare alcune modifiche alle colonne open, high e low. A tale scopo dobbiamo usare le funzionalità offerte dal modulo pandas e ottenere un piccolo aiuto da una funzione del modulo numpy. La formula usata per aggiustare i prezzi è abbastanza semplice. Calcoliamo il fattore di aggiustamento dividendo il valore adj close per il valore close. Possiamo quindi usare il fattore per aggiustare i valori open, high, low e close. Tuttavia, non possiamo eseguire un tradizionale ciclo for sul l’oggetto dataframe, quindi usiamo il modulo numpy. La funzione di vettorizzazione di Numpy ci consente di applicare il metodo adjust() ad ogni riga del dataframe. Si può immaginarlo simile a un ciclo poiché applica la funzione ad ogni riga.
data['Adj Open'] = np.vectorize(adjust)(data['Close'], data['Adj Close'], data['Open'], rounding=args.rounding)
L’arrotondamento permette di garantire che i valori finali siano appropriati per l’asset. L’impostazione di default prevede 4 cifre decimali poiché sono i decimail forniti da Alpha Vantage per le azioni. Nel caso facciamo trading con Crypto o Forex, dobbiamo modificare il parametro di arrotondamento. Infine, eliminiamo i dati non modificati e rinominiamo le colonne in modo che Backtrader riconosca automaticamente quale colonna contiene lo specifico tipo di dato (es. quale colonna è volume).
Esecuzione del codice
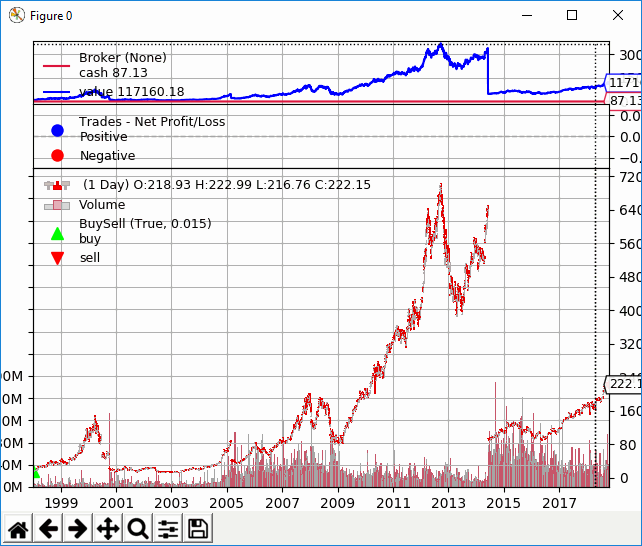
Per verificare come gestire gli split e i dividendi con Backtrader eseguiamo il codice con dati non aggiustati per vedere il punto di partenza. Possiamo farlo con il seguente comando: python3 .\adjusted_data_example.py -s AAPL. (Nota: l’esempio prevede che il file è salvato come adjusted_data_example.py).
Il risultato del backtest è un grafico simile al seguente:
Ora aggiungiamo l’opzione --adjusted in questo modo:
python3 .\adjusted_data_example.py -s AAPL --adjusted
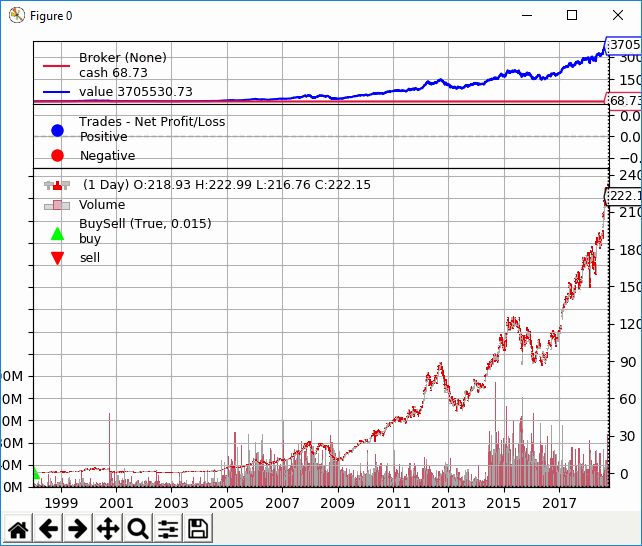
Possiamo vedere che abbiamo risultati molto diversi! Da notare che il PnL finale è pari a un centinaio di migliaia dollari contro più di tre milioni di dollari! Possiamo vedere come i frazionamenti azionari (split) hanno influenzato negativamente i risultati del nostro backtest anche se non avrebbero avuto alcun impatto nel mondo reale. Inoltre, abbiamo ottenuto rendimenti extra dai dividendi ricevuti durante questo periodo.
Poiché stiamo usando l’intero set di dati fornito da Alpha Vantage, i risultati non corrisponderanno esattamente a quelli pubblicati in questo articolo. Apple continuerà a muoversi su e giù in futuro. Se vogliamo vedere solo l’effetto dei dividendi senza gli split dobbiamo o concentrarci su un periodo di tempo specifico, possiamo filtrare i giorni di inizio e fine del backtest modificando:
# Aggiungere i dati a Cerebro
data_in = bt.feeds.PandasData(dataname=data,
timeframe=bt.TimeFrame.Days,
compression=1)
come segue:
# Aggiungere i dati a Cerebro
data_in = bt.feeds.PandasData(dataname=data,
timeframe=bt.TimeFrame.Days,
compressione=1,
dadata=dataora(2016,1,1),
todate=datetime(2017,1,1))
Questa volta, la differenza nell’aspetto del grafico non è così evidente come nell’ultimo esempio. Tuttavia, la differenza in PnL è ancora significativa.
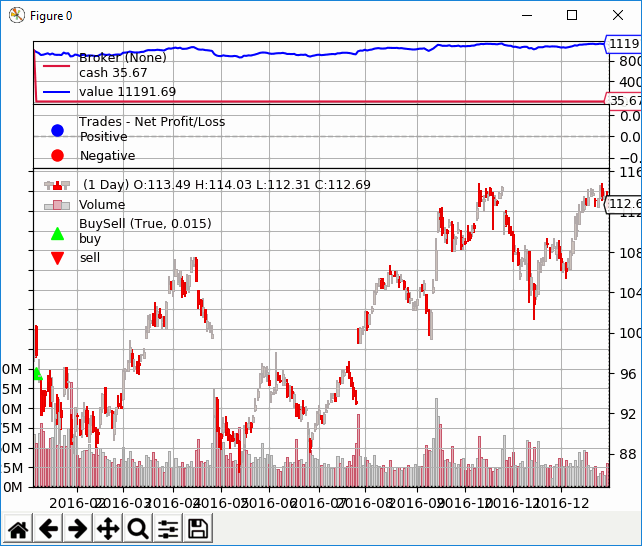
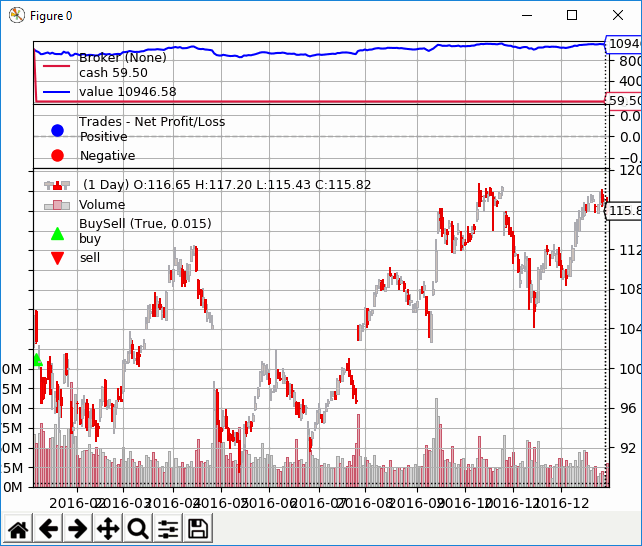
Durante il backtest, i dati non aggiustati hanno restituito un profitto 946,57$ contro un profitto di 1.191,69$ con dati aggiustati. Dobbiamo quindi ricordarci di usare i dati aggiustati ogni volta che eseguiamo un backtest di titoli azionari per un lungo periodo di tempo in modo da includere i profitti derivati dai dividendi!
Codice completo
In questo articolo abbiamo descritto come gestire gli split e i dividendi con Backtrader per analizzare i dati finanziari e costruire strategie di trading algoritmico. Per il codice completo riportato in questo articolo, si può consultare il seguente repository di github:
https://github.com/datatrading-info/BackTrader