Nel precedente articolo relativo alle statistiche bayesiane è stata esaminata la regola di Bayes ed evidenziato come permette di aggiornare razionalmente le convinzioni sull’incertezza dopo aver avuto evidenza di nuove prove. E’ stato inoltre brevemente accennato che tali tecniche stanno diventando estremamente importanti nei campi della data science e della finanza quantitativa.
In questo articolo si vuole ampliare l’esempio del lancio di una moneta, descritto nel precedente articolo, approfondendo le nozioni relativa alle prove di Bernoulli, alla distribuzione beta e alla distribuzione a priori coniugata.
L’obiettivo in questo articolo consiste nel descrivere come eseguire quello che è noto come “inferenza su una proporzione binomiale”, cioè studiare le situazioni probabilistiche con due risultati (ad esempio il lancio di una moneta) e tentare di stimare la proporzione di un insieme ripetuto di eventi che si presentano un risultato “testa” o “croce”.
L’obiettivo è stimare quanto sia equa una moneta. Si usa questa stima per fare previsioni su quante volte uscirà “testa” nei futuri lanci della moneta.
Anche se questo può sembrare un esempio piuttosto accademico, in realtà è sostanzialmente applicabile alle applicazioni del mondo reale più di quanto possa sembrare. Si considera i seguenti scenari:
- Ingegneria: stima della proporzione delle pale delle turbine degli aeromobili che presentano un difetto strutturale dopo la fabbricazione;
- Scienze sociali: stima della percentuale di individui che rispondono “sì” a una domanda di censimento;
- Scienza medica: stima della percentuale dei pazienti che recuperano completamente dopo aver assunto un farmaco sperimentale per curare una malattia;
- Finanza aziendale: stima della percentuale di transazioni errate durante lo svolgimento di audit finanziari
- Data Science: stima della percentuale di individui che fanno clic su un annuncio quando visitano un sito Web.
Come si può vedere, l’inferenza su una proporzione binomiale è una tecnica statistica estremamente importante e costituisce la base di molti degli aspetti avanzati delle statistiche bayesiane.
L'approccio Bayesiano
Dopo aver motivato il concetto di statistiche bayesiane nel precedente articolo, è necessario delineare come procedere l’analisi. Questo motiva le seguenti sezioni (matematicamente piuttosto pesanti) e offre una panoramica su cosa sia un approccio bayesiano.
Come detto sopra, l’obiettivo consiste nel stimare l’equità di una moneta. Una volta ottenuta la stima per l’equità della moneta, si può usarla per prevedere il numero di volte che uscirà “testa” nei futuri lanci della moneta.
Si approfondisce specifiche tecniche specifiche mentre si descrive i seguenti passaggi:
- Presupposti – Si ipotizza che la moneta abbia due esiti (cioè non atterrerà mai su di un lato), i lanci sono completamente casuali ed indipendenti l’uno dall’altro. Inoltre la correttezza della moneta è stazionaria, cioè non cambia nel tempo. Si indica l’equità con il parametro θ.
- Credenze precedenti – Per effettuare un’analisi bayesiana, si deve quantificare le precedenti convinzioni sull’equità della moneta. Questo si riduce a specificare una distribuzione di probabilità sulle convinzioni di questa equità. Si utilizza una distribuzione di probabilità relativamente flessibile chiamata distribuzione beta per modellare le convinzioni.
- Dati sperimentali – Si effettuano alcuni lanci di monete (virtuali) al fine di avere alcuni dati concreti. Si conteggia il numero di teste z che appaiono in N lanci della moneta. Si ha anche bisogno di un modo per determinare la probabilità di tali risultati, data una particolare correttezza, θ, della moneta. Per questo si ha bisogno di discutere le funzioni di verosimiglianza, e in particolare la funzione di verosimiglianza di Bernoulli.
- Credenze a posteriori – Una volta ottenuta una credenza precedente e una funzione di verosimiglianza, si può usare la regola di Bayes per calcolare una credenza a posteriori sull’equità della moneta. Si associa le precedenti credenze con i dati osservati e si aggiorna di conseguenza le convinzioni. Fortunatamente, se si usa una distribuzione beta per le credenze precedenti e una probabilità di Bernoulli, si ottene una distribuzione beta anche a posteriori. Questi sono noti come conjugate priors.
- Inferenza – Dopo aver ottenuto le credenze a posteriori, si può stimare l’equità della moneta θ, prevedere la probabilità delle teste al prossimo lancio o persino vedere come i risultati dipendono da diverse scelte delle credenze precedenti. Quest’ultimo è noto come confronto tra modelli.
Ad ogni fase del processo, si realizza rappresentazioni grafiche per ciascuna di queste funzioni e distribuzioni, utilizzando il pacchetto di grafica Seaborn di Python. Seaborn si basa sulla libreria Matplotlib, ed è ottimizzata per la visualizzazione di dati statistici. Si può dare un’occhiata a questa gallery per avere un’idea sul funzionamento e potenzialità di Seaborn.
Presupposti dell'approccio
Come per tutti i modelli, si devono fare alcune ipotesi sullo scenario di applicazione.
- Si può ipotizzare la moneta possa avere solo due risultati, cioè può atterrare solo sulla sua testa o coda e mai sul suo lato.
- Ogni lancio della moneta è completamente indipendente dagli altri, cioè si hanno lanci indipendenti e identicamente distribuiti.
- La correttezza della moneta non cambia nel tempo, cioè è stazionaria.
Tenendo presente questi presupposti, si può iniziare a discutere la procedura bayesiana.
La Regola di Bayes
La Regola di Bayes applicata all'Inferenza Bayesiana
\( \begin{eqnarray} P(\theta|D) = P(D|\theta) \; P(\theta) \; / \; P(D) \end{eqnarray} \)
dove:- P(θ) è la probabilità a priori, o probabilità marginale, di θ. Questa è la forza nella nostra convinzione su θ senza considerare le prove D. La nostra precedente opinione sulla probabilità che la moneta sia equa e non truccata.
- P(θ|D) è la probabilità a posteriori, o probabilità condizionata. Questa è la forza (raffinata) della nostra convinzione di θ una volta che l’evidenza di D è stata presa in considerazione. Dopo aver visto uscire 4 teste su 8 lanci della moneta, si può dire che questa è la nostra visione aggiornata sulla correttezza della moneta.
- P(D|θ) è la probabilità condizionata di D. Questa è la probabilità di vedere i dati D come generati da un modello con parametro θ. Se si potesse sapere che la moneta era equa e non truccata, la probabilità condizionata di D esprime la probabilità di avere un determinato numero di risultati “testa” per un particolare numero di lanci.
- P(D) è la prova, cioè la probabilità a priori di D, e funge da costante di normalizzazione. Questa è la probabilità dei dati D, determinata come somma (o integrazione) di tutti i possibili valori di θ, ponderati con un indice del grado di confidenza con cui si crede alla validità di quei particolari valori di θ.
La funzione di Verosimiglianza
La Distribuzione di Bernoulli
\( \begin{eqnarray} P(k = 1 | \theta) = f(\theta) \end{eqnarray} \)
Si può scegliere una forma particolarmente succinta per f(θ) semplicemente affermando che la probabilità è data dallo stesso θ, cioè \(f(\theta) = \theta\). Da questo si deduce che la probabilità di avere una “testa” dal lancio di una moneta è pari a:\(\begin{eqnarray} P(k = 1 | \theta) = \theta \end{eqnarray} \)
E la probabilità di avere una “croce” è pari a:\( \begin{eqnarray} P(k = 0 | \theta) = 1-\theta \end{eqnarray} \)
che può anche essere descritto come:\(\begin{eqnarray} P(k | \theta) = \theta^k (1 – \theta)^{1-k} \end{eqnarray} \)
dove \(k \in \{1, 0\}\) e \(\theta \in [0,1]\). Questa è nota come Distribuzione di Bernoulli. Fornisce la probabilità su due valori discreti separati di k per un parametro di equità fisso θ. In sostanza, quantifica la probabilità che esca “testa” o “croce” a seconda di quanto sia equa la moneta.La funzione di Verosimiglianza di Bernoulli
\( \begin{eqnarray} P(k | \theta) = \theta^k (1 – \theta)^{1-k} \end{eqnarray} \)
descrive la probabilità di un risultato fisso k dato un particolare valore di θ. Mentre si modifica θ (ad esempio cambiando l’equità della moneta), si inizia a vedere diverse probabilità per k. Questo è noto come la funzione di verosimiglianza di θ. È una funzione di un θ continuo e si distingue dalla distribuzione di Bernoulli perché quest’ultima è in realtà una distribuzione di probabilità discreta su due potenziali risultati k del lancio della moneta. Da notare che la funzione di verosimiglianza non è in realtà una distribuzione di probabilità poiché l’integrazione di tutti i valori del parametro di equità θ in realtà non è uguale a 1, come richiesto per una distribuzione di probabilità. Si definisce \(P(k | \theta) = \theta^k (1 – \theta)^{1-k}\) come la funzione di verosimiglianza di Bernoulli per θ.Lanci Multipli della moneta
\( \begin{eqnarray} P(\{k_1, …, k_N\} | \theta) &=& \prod_{i} P(k_i | \theta) \\ &=& \prod_{i} \theta^{k_i} (1 – \theta)^{1-{k_i}} \end{eqnarray} \)
Per esempio, se si è interessati al numero di “teste” uscite in N lanciChe dire se siamo interessati al numero di teste, dato z il numero di teste uscite, allora la formula sopra diventa:\( \begin{eqnarray} P(z, N | \theta) = \theta^z (1 – \theta)^{N-z} \end{eqnarray} \)
Cioè, la probabilità di avere z “teste” in N lanci, assumendo un parametro di equità θ. Si userà questa formula per determinare la distribuzione delle credenze posteriori, come descritto più avanti in questo articolo.Quantificare le Credenze a Priori
Distribuzione Beta
\( \begin{eqnarray} P(\theta | \alpha, \beta) = \theta^{\alpha – 1} (1 – \theta)^{\beta – 1} / B(\alpha, \beta) \end{eqnarray} \)
Dove il termine nel denominatore, \(B(\alpha, \beta)\), agisce come una costante normalizzante in modo che l’area sotto il PDF abbia in realtà somma pari a 1. Nel grafico seguente si rappresentano diverse distribuzione beta a seconda dei parametri α e β: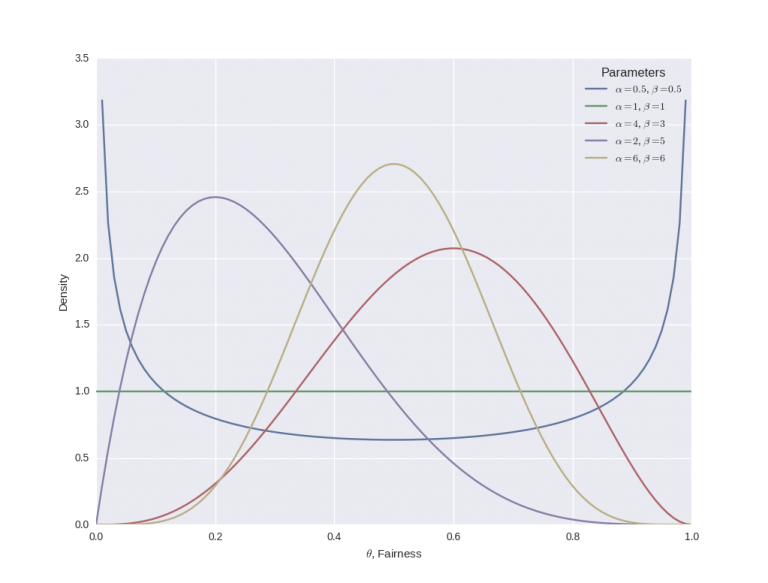
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
import seaborn as sns
if __name__ == "__main__":
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
x = np.linspace(0, 1, 100)
params = [
(0.5, 0.5),
(1, 1),
(4, 3),
(2, 5),
(6, 6)
]
for p in params:
y = beta.pdf(x, p[0], p[1])
plt.plot(x, y, label="$\\alpha=%s$, $\\beta=%s$" % p)
plt.xlabel("$\\theta$, Fairness")
plt.ylabel("Density")
plt.legend(title="Parameters")
plt.show()
Essenzialmente, quando α diventa più grande, la maggior parte della distribuzione di probabilità si muove verso destra (una moneta truccata per avere più “teste”), mentre un aumento di β sposta la distribuzione verso sinistra (una moneta truccata per avere più “croci”) .
Tuttavia, se si aumenta sia α che β, la distribuzione inizia a restringersi. Se α e β aumentano ugualmente, allora la distribuzione raggiungerà un picco per θ = 0,5, cioè quando la moneta è equa.
Perché si è scelto la funzione beta come probabilità a priori? Ci sono un paio di motivi:
- Supporto – La funzione è definito nell’intervallo [0,1], lo stesso intervallo di esistenza di θ.
- Flessibilità – Possiede due parametri di forma conosciuti come α e β, che gli conferiscono una notevole flessibilità. Questa flessibilità offre una vasta scelta delle modalità per modelliamo le credenze.
Tuttavia, la ragione più importante per scegliere una distribuzione beta è dovuta al fatto che questa è una distribuzione a priori congiunta (conjugate prior) per la distribuzione di Bernoulli.
Distribuzione a Priori Coniugata
\( \begin{eqnarray} P(\theta | D) \propto P(D|\theta) P(\theta) \end{eqnarray} \)
Una distribuzione a priori coniugata è una possibile scelta per descrivere la probabilità a priori perché, quando accoppiata con uno specifico tipo di funzione di verosimiglianza, fornisce una distribuzione a posteriori appartenente alla stessa famiglia della distribuzione a priori. Sia a priori che sia a posteriori hanno la stessa famiglia di distribuzione di probabilità, ma con parametri diversi. I conjugate prior sono estremamente convenienti dal punto di vista del calcolo poiché forniscono espressioni di forma chiusa per la distribuzione a posteriori, annullando in tal modo qualsiasi complessa integrazione numerica. Per il nostro esempio, se si usa una funzione di verosimiglianza di Bernoulli e una distribuzione beta come descrivere la probabilità a priori si ottiene immediatamente che la probabilità a posteriori sarà anch’essa una distribuzione beta. L’utilizzo di una distribuzione beta per la probabilità a priori implica la possibilità di effettuare lanci di monete sperimentali e perfezionare direttamente le convinzioni. La probabilità a posteriori diventerà la nuova probabilità a priori ed è possibile usare la regola di Bayes in successione quando vengono generati nuovi lanci di monete. Se la precedente credenza è specificata da una distribuzione beta e si ha una funzione di verosimiglianza di Bernoulli, allora anche la probabilità a posteriori sarà anche una distribuzione beta. Da notare tuttavia che un priore è solo coniugato rispetto a una particolare funzione di probabilità.Perché coniugare una Distribuzione Beta con una funzione di Verosimiglianza di Bernoulli?
\( \begin{eqnarray} P(\theta | \alpha, \beta) = \theta^{\alpha – 1} (1 – \theta)^{\beta – 1} / B(\alpha, \beta) \end{eqnarray} \)
Da notare che la forma della distribuzione beta è simile alla forma di una verosimiglianza di Bernoulli. Infatti, se si moltiplicano le due forme (come nella regola di Bayes), si ottiene:\( \begin{eqnarray} \theta^{\alpha – 1} (1 – \theta)^{\beta – 1} / B(\alpha, \beta) \times \theta^{k} (1 – \theta)^{1-k} \propto \theta^{\alpha + k – 1} (1 – \theta)^{\beta + k} \end{eqnarray} \)
Il termine sul lato destro del segno di proporzionalità ha la stessa forma del prior (a meno di una costante normalizzante).Differenti modi per specificare una Distribuzione Beta
\( \begin{eqnarray} \mu = \frac{\alpha}{\alpha + \beta} \end{eqnarray} \)
Mentre la deviazione standard σ è data da:\( \begin{eqnarray} \sigma = \sqrt{\frac{\alpha \beta}{(\alpha + \beta)^2 (\alpha + \beta + 1)}} \end{eqnarray} \)
Quindi, riorganizzando queste formule per fornire α e β in termini di μ e σ. α si ottiene:\( \begin{eqnarray} \alpha = \left( \frac{1-\mu}{\sigma^2} – \frac{1}{\mu} \right) \mu^2 \end{eqnarray} \)
Mentre β è dato da:\( \begin{eqnarray} \beta = \alpha \left( \frac{1}{\mu} – 1 \right) \end{eqnarray} \)
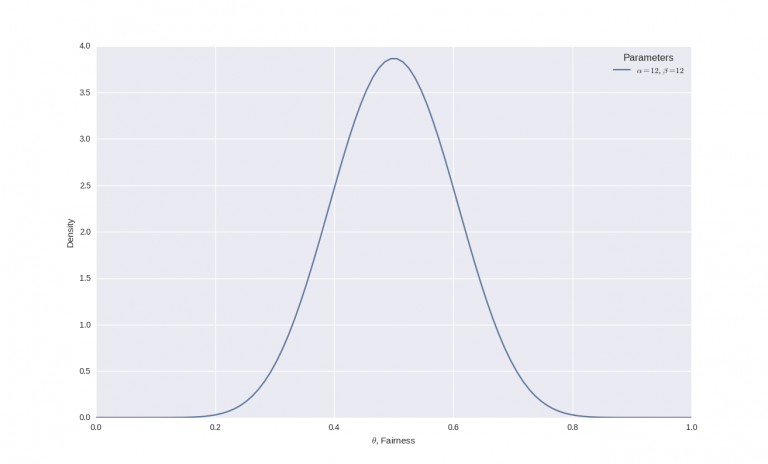
In questo passaggio è necessario prestare molta attenzione perché non è possibile specificare un σ > 0,289, dato che questa è la deviazione standard di una densità uniforme (che implica nessuna credenza precedente su ogni specifica equità della moneta). Ad esempio, se si ipotizza una equità della moneta intorno allo 0,5, ma senza l’assoluta certezza. Si può specificare una deviazione standard di circa 0,1. Quale distribuzione beta sarà prodotta come risultato? Inserendo i numeri nelle formule si ottine α = 12 e β = 12 e la distribuzione beta è simile alla seguente: