
In questo articolo descriviamo come creare un set di dati per l’S&P500 senza il bias di sopravvivenza in Python per migliorare il backtest di strategie di trading algoritmico e quantitativo.
Quando si sviluppa una strategia di trading azionario, è importante che il backtest sia il più accurato possibile. In alcune delle strategie descritte nei precedenti articoli, abbiamo notato che il backtest non teneva conto del bias di sopravvivenza. Il survivorship bias (o bias di sopravvivenza) è una forma di bias di selezione causata dal concentrarsi solo su asset che hanno già superato una sorta di processo selettivo.
Un semplice esempio è una strategia che semplicemente acquista e mantiene un’equa allocazione degli attuali componenti dell’S&P500.
Il dataset dell’S&P500
Possiamo utilizzare i dati S&P 500 di un articolo precedente. Possiamo quindi confrontare la performance di questa strategia con le performance di RSP, un ETF che replica l’indice S&P 500 Equal Weight.
import matplotlib.pyplot as plt
import pandas as pd
import yfinance as yf
tickers = pd.read_csv('spy/tickers.csv', header=None)[1].tolist()
# calcola il prodotto cumulativo della media di tutti i rendimenti giornalieri
# ovvero simulare una crescita di $1 pesando equamente tutti gli attuali
# componenti dell'indice S&P 500
sim_rsp = (
(pd.concat(
[pd.read_csv(f"spy/{ticker}.csv", index_col='date', parse_dates=True)[
'close'
].pct_change()
for ticker in tickers],
axis=1,
sort=True,
).mean(axis=1, skipna=True) + 1)
.cumprod()
.rename("SIM")
)
# scarida i dati di RSP
rsp = (
(yf.download("RSP", sim_rsp.index[0], sim_rsp.index[-1])[
"Adj Close"
].pct_change() + 0.002 / 252 + 1) # ER annuale del 0.20%
.cumprod()
.rename("RSP")
)
sim_rsp.plot(legend=True, title="RSP vs. Survivorship-Biased Strategy", figsize=(12, 9))
rsp.plot(legend=True)
plt.show()
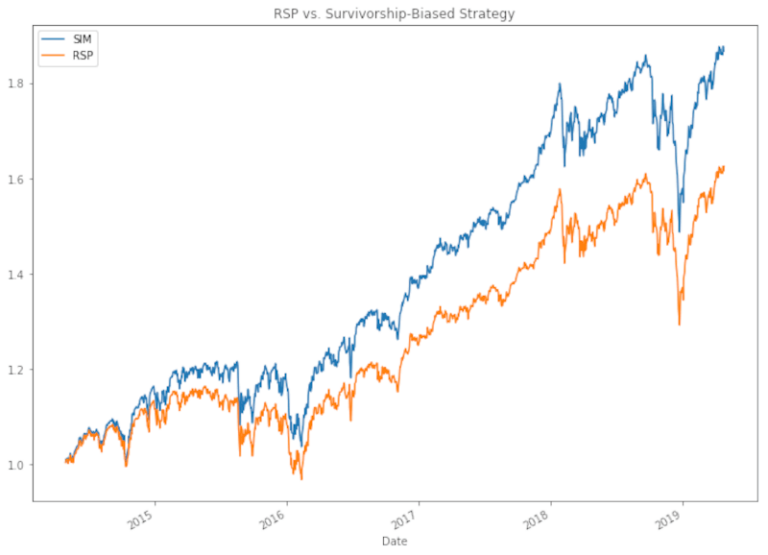
Se avessimo iniziato a fare trading con questa strategia nel 2014 avremmo facilmente battuto il mercato. Dobbiamo solo conoscere i componenti dell’S&P 500 tra 5 anni… Questo semplice esempio mostra come un trader possa essere indotto con l’inganno a pensare di avere una buona strategia perché non ha tenuto conto del survival bias.
Dati privi del bias di sopravvivenza
Come possiamo creare prevenire il bias di sopravvivenza? È più facile a dirsi che a farsi. Per creare un set di dati per l’S&P500 senza il bias di sopravvivenza, dobbiamo prima conoscere tutti i componenti storici dell’S&P 500 nell’arco temporale desiderato. Una volta che conosciamo tutti i componenti, possiamo mettere insieme un set di dati utilizzando i dati storici sui prezzi di tutti i componenti durante il periodo di tempo in cui erano nell’S&P 500.
Sfortunatamente ci sono alcuni ostacoli che rendono la raccolta dei dati più difficile di quanto ci si potrebbe aspettare. Innanzitutto, è difficile ottenere dati storici sui componenti dell’indice S&P 500. I componenti attuali possono essere recuperati da Wikipedia, ma trovare componenti storici è quasi impossibile senza acquistare i dati. In secondo luogo, una volta che si conoscono i componenti storici, anche trovare dati sui prezzi può essere difficile. Le società dell’indice S&P 500 vengono periodicamente rinominate, acquisite e alcune addirittura falliscono. Le fonti di dati gratuite come Yahoo Finance di solito non dispongono di dati sui titoli cancellati; Anche i cambiamenti storici dei nomi dei ticker non sono ben documentati.
Origine dei dati
Costituenti
Anche se non disponiamo di dati storici reali sui componenti, possiamo fare una buona approssimazione utilizzando il portafoglio di un ETF che segue l’indice S&P 500. L’ETF iShares Core S&P 500 (IVV) rende pubbliche le sue partecipazioni ogni mese e dichiara di investire almeno il 90% delle sue attività in titoli dell’indice. Con un po’ di web scraping possiamo facilmente ottenere le sue partecipazioni mensili dal 2006.
import requests
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
import json
# request di una pagina
html = requests.get("https://www.ishares.com/us/products/239726/#tabsAll").content
soup = BeautifulSoup(html)
# cerca le date disponibili
holdings = soup.find("div", {"id": "holdings"})
dates_div = holdings.find_all("div", "component-date-list")[1]
dates_div.find_all("option")
dates = [option.attrs["value"] for option in dates_div.find_all("option")]
# scarica i costituenti per ogni data
constituents = pd.Series()
for date in dates:
resp = requests.get(
f"https://www.ishares.com/us/products/239726/ishares-core-sp-500-etf/1467271812596.ajax?tab=all&fileType=json&asOfDate={date}"
).content[3:]
tickers = json.loads(resp)
tickers = [(arr[0], arr[1]) for arr in tickers['aaData']]
date = datetime.strptime(date, "%Y%m%d")
constituents[date] = tickers
constituents = constituents.iloc[::-1] # inverte in ordine cronologico
constituents.head()
2006-09-29 [(PMCS, PMC-SIERRA INC.), (ANDW, ANDREW CORP.)...
2006-10-31 [(PMCS, PMC-SIERRA INC.), (PGL, PEOPLES ENERGY...
2006-11-30 [(PMCS, PMC-SIERRA INC.), (ADCT, ADC TELECOMMU...
2006-12-29 [(PMCS, PMC-SIERRA INC.), (ADCT, ADC TELECOMMU...
2007-01-31 [(PMCS, PMC-SIERRA INC.), (PGL, PEOPLES ENERGY...
dtype: object
Come possiamo vedere, per ogni mese abbiamo una lista di tutti i ticker e i nomi delle società detenuti nell’ETF. Possiamo ora scaricare i dati storici dei prezzi.
Dati sui prezzi
Come accennato in precedenza, recuperare i dati storici per tutti i componenti dell’indice può essere difficile. Fortunatamente per noi, il set di dati dei prezzi WIKI di Quandl contiene la maggior parte dei dati di cui abbiamo bisogno. Sebbene il feed di dati non sia più aggiornato, contiene ancora dati accurati precedenti ad aprile 2018. Possiamo esportare i dati dopo aver creato un account gratuito. Dopo aver scaricato i dati li possiamo separare per ogni titolo.
wiki = pd.read_csv("WIKI_PRICES.csv", parse_dates=True)
wiki = dict(tuple(wiki.groupby('ticker')))
for ticker in wiki:
wiki[ticker].set_index("date", inplace=True)
Sebbene il set di dati WIKI contenga la maggior parte dei dati di cui abbiamo bisogno, non li ha tutti. Usiamo Yahoo Finance per scaricare i dati rimanenti. Scriviamo alcune funzioni di supporto per aiutarci a scaricare i dati.
import time
import re
def quandl_data(ticker, start, end):
if ticker in wiki:
df = wiki[ticker][start:end]
else:
ticker = fix_ticker(ticker)
if ticker in wiki:
df = wiki[ticker][start:end]
else:
return None
df = df.drop(['open','high','low','close', 'volume','ex-dividend','split_ratio', 'ticker'], axis=1)
df = df.rename(index=str, columns={"adj_open": "open",
"adj_high": "high",
"adj_low": "low",
"adj_close": "close",
"adj_volume": "volume"})
return df
def yahoo_data(ticker, start, end):
ticker = fix_ticker(ticker)
try:
df =yf.download(ticker, start, end)
except:
time.sleep(1)
try:
df = yf.download(ticker, start, end)
except:
return None
# aggiustare i dati ohlc usando adj close
adjfactor = df["Close"] / df["Adj Close"]
df["Open"] /= adjfactor
df["High"] /= adjfactor
df["Low"] /= adjfactor
df["Close"] = df["Adj Close"]
df["Volume"] *= adjfactor
df = df.drop(["Adj Close"], axis=1)
df = df.rename(str.lower, axis='columns')
df.index.rename('date', inplace=True)
return df
def fix_ticker(ticker):
rename_table = {
"-": "LPRAX", # BlackRock LifePath Dynamic Retirement Fund
"8686": "AFL", # AFLAC
"4XS": "ESRX", # Express Scripts Holding Company
"AAZ": "APC", # Anadarko Petroleum Corporation
"AG4": "AGN", # Allergan plc
"BFB": "BF_B", # Brown-Forman Corporation
"BF.B": "BF_B", # Brown-Forman Corporation
"BF/B": "BF_B", # Brown-Forman Corporation
"BLD WI": "BLD", # TopBuild Corp.
"BRKB": "BRK_B", # Berkshire Hathaway Inc.
"CC WI": "CC", # The Chemours Company
"DC7": "DFS", # Discover Financial Services
"GGQ7": "GOOG", # Alphabet Inc. Class C
"HNZ": "KHC", # The Kraft Heinz Company
"LOM": "LMT", # Lockheed Martin Corp.
"LTD": "LB", # L Brands Inc.
"LTR": "L", # Loews Corporation
"MPN": "MPC", # Marathon Petroleum Corp.
"MWZ": "MET", # Metlife Inc.
"MX4A": "CME", # CME Group Inc.
"NCRA": "NWSA", # News Corporation
"NTH": "NOC", # Northrop Grumman Crop.
"PA9": "TRV", # The Travelers Companies, Inc.
"QCI": "QCOM", # Qualcomm Inc.
"RN7": "RF", # Regions Financial Corp
"SLBA": "SLB", # Schlumberger Limited
"SYF-W": "SYF", # Synchrony Financial
"SWG": "SCHW", # The Charles Schwab Corporation
"UAC/C": "UAA", # Under Armour Inc Class A
"UBSFT": "UBSFY", # Ubisoft Entertainment
"USX1": "X", # United States Steel Corporation
"UUM": "UNM", # Unum Group
"VISA": "V", # Visa Inc
}
if ticker in rename_table:
fix = rename_table[ticker]
else:
fix = re.sub(r'[^A-Z]+', '', ticker)
return fix
Abbiamo creato un grande dizionario rename_table. Come accennato in precedenza, le aziende possono cambiare i ticker dei loro titoli azionari e spesso non è ben documentato. Abbiamo creato manualmente una mappa dal vecchio al nuovo simbolo del ticker. Questo approccio aggiunge una componente di errore umano.
Compilazione dei dati
Ora siamo pronti per compilare tutti i dati usando la lista dei componenti! Memorizziamo anche le azioni con dati mancanti nella lista skips.
data = {}
skips = set()
constituents = constituents['2013-02-28':'2018-02-28']
for i in range(0, len(constituents) - 1):
start = str(constituents.index[i].date())
end = str((constituents.index[i + 1].to_pydatetime() - timedelta(days=1)).date())
for company in constituents[i]:
if company in skips:
continue
df = quandl_data(company[0], start, end)
if df is None:
df = yahoo_data(company[0], start, end)
if df is None:
skips.add(company)
continue
if company[0] in data:
data[company[0]] = data[company[0]].append(df)
else:
data[company[0]] = df
Otteniamo i seguenti dati all’interno della lista skips.
{('ACT', 'ACTAVIS INC.'),
('ACT', 'ACTAVIS PLC'),
('BLKFDS', 'BLK CSH FND TREASURY SL AGENCY'),
('BMC', 'BMC SOFTWARE INC.'),
('CVH', 'COVENTRY HEALTH CARE INC'),
('ESH5', 'S&P500 EMINI MAR 15'),
('ESH6', 'S&P500 EMINI MAR 16'),
('ESH7', 'S&P500 EMINI MAR 17'),
('ESH8', 'S&P500 EMINI MAR 18'),
('ESM5', 'S&P500 EMINI JUN 15'),
('ESM6', 'S&P500 EMINI JUN 16'),
('ESM7', 'S&P500 EMINI JUN 17'),
('ESU5', 'S&P500 EMINI SEP 15'),
('ESU6', 'S&P500 EMINI SEP 16'),
('ESU7', 'S&P500 EMINI SEP 17'),
('ESZ4', 'S&P500 EMINI DEC 14'),
('ESZ5', 'S&P500 EMINI DEC 15'),
('ESZ6', 'S&P500 EMINI DEC 16'),
('ESZ7', 'S&P500 EMINI DEC 17'),
('HAWKB', 'BLACKHAWK NETWORK HOLDINGS INC CLA'),
('MARGIN_USD', 'FUTURES USD MARGIN BALANCE'),
('MOLX', 'MOLEX INC.'),
('NYX', 'NYSE EURONEXT'),
('PCS', 'METROPCS COMMUNICATIONS INC.'),
('UBFUT', 'CASH COLLATERAL USD UBFUT')}
Come possiamo vedere, ci sono alcune società per le quali non siamo riusciti a ottenere dati perché nel frattempo sono state acquisite. Potrebbe essere possibile trovare i dati da una fonte diversa, ma manteniamo ciò che abbiamo finora. Inoltre, notiamo che l’ETF deteneva occasionalmente futures S&P 500 e garanzie collaterali in contanti, che fanno parte di meno del 10% delle partecipazioni non incluse nell’indice.
Esportazione
Ora possiamo esportare nuovamente i nostri dati in CSV.
for ticker, df in data.items():
df = df.reset_index().drop_duplicates(subset='date').set_index('date')
df.to_csv(f"survivorship-free/{fix_ticker(ticker)}.csv")
data[ticker] = df
tickers = [fix_ticker(ticker) for ticker in data.keys()]
pd.Series(tickers).to_csv("survivorship-free/tickers.csv")
Test
Ora che disponiamo di dati privi del bias di sopravvivenza, testiamoli rispetto all’RSP, l’ETF dell’S&P 500 equi-pesato usato in precedenza.
sim_rsp = (
(pd.concat(
[pd.read_csv(f"survivorship-free/{ticker}.csv", index_col='date', parse_dates=True)[
'close'
].pct_change()
for ticker in tickers],
axis=1,
sort=True,
).mean(axis=1, skipna=True) + 1)
.cumprod()
.rename("SIM")
)
rsp = (
(web.DataReader("RSP", "yahoo", sim_rsp.index[0], sim_rsp.index[-1])[
"Adj Close"
].pct_change() + 0.002 / 252 + 1) # 0.20% annual ER
.cumprod()
.rename("RSP")
)
sim_rsp.plot(legend=True, title="RSP vs. Un-Survivorship-Biased Strategy", figsize=(12, 9))
rsp.plot(legend=True);
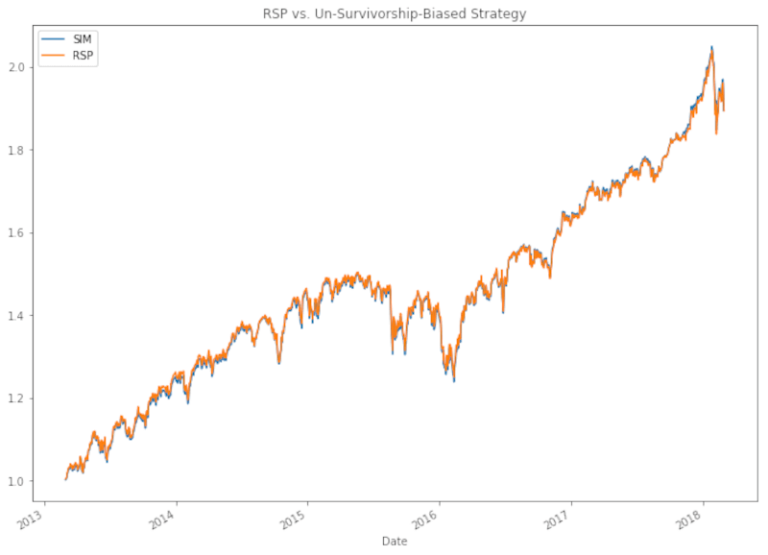
Le linee sono quasi identiche! Sebbene il nostro set di dati non sia storicamente accurato al 100%, è sicuramente un approccio migliore rispetto al semplice utilizzo degli attuali componenti dell’S&P 500. Ora che disponiamo di un set di dati privo del bias di sopravvivenza, possiamo testare le future strategie con maggiore precisione.
Codice completo
In questo articolo abbiamo descritto come creare un set di dati per l’S&P500 senza il bias di sopravvivenza in Python. Per il codice completo riportato in questo articolo, si può consultare il seguente repository di github:
https://github.com/datatrading-info/AnalisiDatiFinanziari

