In questo articolo descriviamo le ultime modifiche che abbiamo inserito nel sistema di trading sul mercato forex. In particolare abbiamo aggiunto alcune nuove funzionalità tra cui:
- Documentazione : ora ho creato una sezione DTForex sul sito, che include tutti gli articoli della serie sul trading algoritmo per il Forex e la documentazione per DTForex. In particolare, include istruzioni dettagliate per l’installazione e una guida all’uso sia per il backtesting che per il trading dal vivo.
- Generazione di dati tick simulati – Dal momento che è difficile scaricare in blocco molti dati tick sul forex (o almeno per alcuni dei data provider che uso!) ho deciso che sarebbe stato più semplice generare semplicemente alcuni dati tick casuali per testare il sistema.
- Backtest di più giorni – Una funzionalità essenziale per il sistema DTForex è la capacità di eseguire il backtest su più giorni di dati tick. L’ultima versione di DTForex supporta sia il backtesting di più giorni che quello di più coppie di valute, rendendolo sostanzialmente più utile.
- Tracciare i risultati del backtesting – Sebbene l’output della console sia utile, niente batte la possibilità di visualizzare una curva di equity e un drawdown storico. Ho utilizzato la libreria Seaborn per tracciare i vari grafici delle prestazioni.
Script per Simulare i Dati di Tick
Una caratteristica estremamente importante per un sistema di trading è la capacità di eseguire un backtest su dati di tick storici che coprono un periodo di tempo di più giorni . In precedenza il sistema prevedeva solo il backtest tramite un singolo file. Questa non era una soluzione scalabile in quanto tale file deve essere caricato in memoria e poi strutturato in DataFrame di pandas . Sebbene i file di dati dei tick prodotti non siano enormi (circa 3,5 MB ciascuno), si sommano rapidamente se consideriamo più coppie di valute per periodi di mesi o anche più.
Per iniziare a creare una funzionalità per più giorni / più file, si inizia a scaricare più file dal feed tick storico di DukasCopy . Purtroppo ho avuto qualche problema e non sono riuscito a scaricare i file necessari per testare il sistema.
Dal momento che non è essenziale avere serie temporali storiche per testare il sistema, può essere più semplice scrivere uno script per generare automaticamente dei dati di tick simulati. Questo script è stato inserito nel file scripts/generate_simulated_pair.py. Il codice può essere visionato qui .
L’idea di base dello script è generare un elenco di timestamp distribuiti in modo casuale, ognuno dei quali possiede sia valori bid/ask che valori di volume. Lo spread tra l’offerta e la domanda è costante, mentre i valori bid / ask stessi sono generati come un random walk.
Dal momento che non si testerà mai alcuna strategia reale con questi dati, non c’è bisogno di preoccuparsi delle sue proprietà statistiche o dei suoi valori assoluti in relazione alle coppie di valute forex reali. Finché si garantisce il corretto formato e una lunghezza approssimativa, si può usare per testare il sistema di backtesting di più giorni.
Lo script è attualmente codificato per generare dati forex per l’intero mese di gennaio 2017. Utilizza la libreria Calendar di Python per considerare i giorni lavorativi (anche se non abbiamo ancora escluso le festività) e quindi genera una serie di file nel formato BBBQQQ_YYYYMMDD.csv, dove BBBQQQsarà una specifica coppia di valute specificata (es. EURUSD) ed YYYYMMDD è la data specificata (es 20170112.).
Questi file vengono inseriti nella directory CSV_DATA_DIR, che è specificata file settings.py dell’applicazione.
Per generare i dati è necessario eseguire il seguente comando, dove BBBQQQdeve essere sostituito con lo specifico della valuta di interesse, es EURUSD:
python scripts/generate_simulated_pair.py BBBQQQ
Il file richiederà una modifica per generare dati per più mesi o anni. Ogni file di tick giornalieri ha una dimensione dell’ordine di 3,2 MB.
In futuro si modificherà questo script per generare dati per un periodo di più mesi o anni in base a uno specifico elenco di coppie di valute, anziché i valori codificati. Tuttavia, per il momento questo è sufficiente per iniziare.
Si tenga presente che il formato corrisponde esattamente a quello dei dati storici dei tick forniti da DukasCopy, che è il set di dati che stiamo attualmente utilizzando.
Implementazione di un Backtesting per più giorni
Successivamente alla generazione di dati tick simulati, si passa all’implementazione del backtesting per più giorni. Sebbene il piano a lungo termine prevede di utilizzare un sistema di archiviazione di dati storico più robusto come PyTables con HDF5 , per il momento si utilizza un set di file CSV, un file per ogni giorno per ogni coppia di valute.
Questa è una soluzione scalabile all’aumentare del numero di giorni. La natura event-driven del sistema richiede che siano presenti solo \(N\) file in memoria contemporaneamente, dove \(N\) è il numero di coppie di valute scambiate in un particolare giorno.
L’idea di base del sistema prevede che la classe HistoricCSVPriceHandler continui a utilizzare il metodo stream_next_tick, ma con una modifica per tenere conto di dati per più giorni caricando ogni giorno di dati in modo sequenziale.
L’implementazione prevede di terminare il backtest quando si riceve l’eccezione StopIteration generata dal metodo next(..) per self.all_pairs come mostrato in questo frammento di pseudocodice:
# price.py
..
..
def stream_next_tick(self):
..
..
try:
index, row = next(self.all_pairs)
except StopIteration:
return
else:
..
..
# Aggiungere un tick alla coda
Nella nuova implementazione, questo snippet viene modificato come segue:
# price.py
..
..
def stream_next_tick(self):
..
..
try:
index, row = next(self.cur_date_pairs)
except StopIteration:
# Fine dei dati per l'attuale giorno
if self._update_csv_for_day():
index, row = next(self.cur_date_pairs)
else: # Fine dei dati
self.continue_backtest = False
return
..
..
# Aggiunta del tick nella coda
In questo frammento, quando viene generato un StopIteration, il codice verifica il risultato di self._update_csv_for_day(). Se il risultato è True il backtest continua (il self.cur_date_pairs, che potrebbe essere stato modificato nei dati dei giorni successivi). Se il risultato è False, il backtest termina.
Questo approccio è molto efficiente in termini di memoria poiché solo un limitato numero di giorni di dati è caricato in un punto qualsiasi. Significa che possiamo potenzialmente eseguire mesi di backtesting e siamo limitati solo dalla velocità di elaborazione della CPU e dalla quantità di dati che possiamo generare o acquisire.
Abbiamo quindi aggiornato la documentazione per riflettere il fatto che il sistema ora si aspetta più giorni di dati in un formato particolare, in una directory particolare che deve essere specificata.
Rappresentazione Grafica dei Risultati del Backtest tramite la libreria Seaborn
Un backtest è relativamente inutile se non siamo in grado di visualizzare le prestazioni della strategia nel tempo. Sebbene il sistema sia stato per lo più basato su console fino ad oggi, in questo articolo iniziamo ad introdurre le basi per un’interfaccia utente grafica (GUI).
In particolare, iniziamo con creare i soliti “tre pannelli” di grafici che spesso accompagnano le metriche di performance per i sistemi di trading quantitativo, vale a dire la curva equity, il profilo dei rendimenti e la curva dei drawdown. Tutti e tre vengono calcolati per ogni tick e vengono emessi in un file chiamato equity.csv nella directory specificata in OUTPUT_RESULTS_DIR presente in settings.py.
Per visualizzare i dati utilizziamo una libreria chiamata Seaborn , che produce grafica di qualità elevata che ha un aspetto sostanzialmente migliore rispetto ai grafici predefiniti prodotti da Matplotlib. La grafica è molto simile a quella prodotta dal pacchetto ggplot2 di R. Inoltre Seaborn si basa effettivamente su Matplotlib, quindi si puo ancora utilizzare l’API Matplotlib.
Per consentire la visualizzazione dei risultati abbiamo creato lo script output.py che risiede nella directory backtest/. Il codice dello script è il seguente:
# output.py
import os, os.path
import pandas as pd
import matplotlib
try:
matplotlib.use('TkAgg')
except:
pass
import matplotlib.pyplot as plt
import seaborn as sns
from qsforex.settings import OUTPUT_RESULTS_DIR
if __name__ == "__main__":
"""
A simple script to plot the balance of the portfolio, or
"equity curve", as a function of time.
It requires OUTPUT_RESULTS_DIR to be set in the project
settings.
"""
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
equity_file = os.path.join(OUTPUT_RESULTS_DIR, "equity.csv")
equity = pd.io.parsers.read_csv(
equity_file, parse_dates=True, header=0, index_col=0
)
# Plot three charts: Equity curve, period returns, drawdowns
fig = plt.figure()
fig.patch.set_facecolor('white') # Set the outer colour to white
# Plot the equity curve
ax1 = fig.add_subplot(311, ylabel='Portfolio value')
equity["Equity"].plot(ax=ax1, color=sns.color_palette()[0])
# Plot the returns
ax2 = fig.add_subplot(312, ylabel='Period returns')
equity['Returns'].plot(ax=ax2, color=sns.color_palette()[1])
# Plot the returns
ax3 = fig.add_subplot(313, ylabel='Drawdowns')
equity['Drawdown'].plot(ax=ax3, color=sns.color_palette()[2])
# Plot the figure
plt.show()
Come puoi vedere, lo script importa Seaborn e apre il file equity.csv in un DataFrame pandas, quindi crea semplicemente tre grafici, rispettivamente per la curva di equity, i rendimenti e il drawdown.
Nota che il grafico di drawdown stesso è effettivamente calcolato da una funzione di supporto che risiede performance/performance.py, che viene chiamata dalla classe Portfolio alla fine di un backtest.
Un esempio dell’output per la strategia MovingAverageCrossStrategy, per un set di dati di EURUSD generato casualmente per il mese di gennaio 2017, è il seguente:
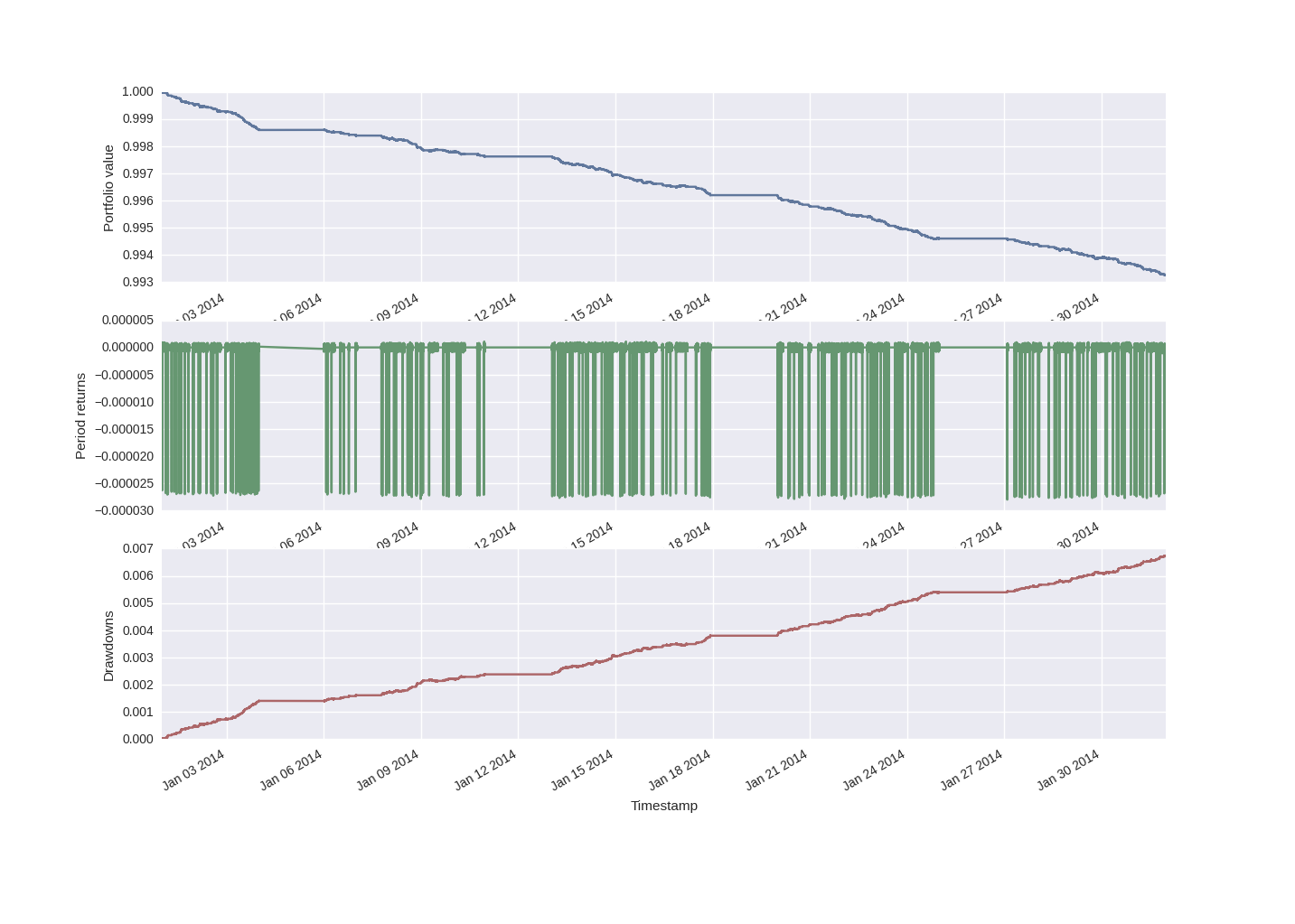
In particolare, è possibile vedere le sezioni piatte della curva azionaria nei fine settimana in cui non sono presenti dati (almeno, per questo set di dati simulato). Inoltre, la strategia perde denaro in modo piuttosto prevedibile su questo set di dati simulato in modo casuale.
Questo è un buon test del sistema. Stiamo semplicemente tentando di seguire una tendenza su una serie temporale generata casualmente. Le perdite si verificano a causa dello spread fisso introdotto nel processo di simulazione.
Ciò rende palese che se vogliamo realizzare un profitto consistente nel trading forex con frequenze più alte avremo bisogno di uno specifico vantaggio quantificabile che generi rendimenti positivi oltre i costi di transazione come spread e slippage.
Avremo molto altro da dire su questo punto estremamente importante nei prossimi articoli di questa serie sul trading algoritmico del Forex.
Prossimi Passi
Calcoli della posizione di fissaggio
Abbiamo notato che i calcoli effettuati dalla classe Position non rispecchiano esattamente il modo in cui OANDA (il broker utilizzato per il sistema trading.py) calcola i trade di cross valutari.
Quindi, uno dei passaggi successivi più importanti è eseguire e testare effettivamente le nuove modifiche al file position.py e aggiornare anche gli unit test implementati in position_test.py. Questo avrà un effetto a catena sui file portfolio.py e portfolio_test.py.
Valutazione della prestazione
Sebbene ora disponiamo di un set di base di grafici delle prestazioni tramite la curva di equity, il profilo dei rendimenti e le serie dei drawdown, abbiamo bisogno di misure di performance più quantificate.
In particolare, avremo bisogno di metriche a livello di strategia, inclusi i comuni rapporti di rischio/rendimento come lo Sharpe Ratio, Information Ratio e Sortino Ratio. Avremo anche bisogno di statistiche sul drawdown inclusa la distribuzione dei drawdown, oltre a statistiche descrittive come il massimo drawdown. Altre metriche utili includono il tasso di crescita annuale composto (CAGR) e il rendimento totale.
A livello di trade/posizione vogliamo vedere metriche come il profitto/perdita medio, il profitto/perdita massimo, rapporto di profitto e rapporto di vincita / perdita. Dal momento che abbiamo costruito fin dall’inizio la classe Position come parte fondamentale del software, non dovrebbe essere troppo problematico generare queste metriche tramite alcuni metodi aggiuntivi.
Per il codice completo riportato in questo articolo, utilizzando il modulo di backtesting event-driven per il forex (DTForex) si può consultare il seguente repository di github:
https://github.com/datatrading-info/DTForex