In questo articolo descriviamo come creare un grafico candlestick con Plotly e AlphaVantage.
L’AlphaVantage
AlphaVantage è stata fondata nel 2017 in seguito alla scomparsa dell’API Yahoo Finance. Offre dati OHLC su oltre 100.000 titoli azionari, ETF e fondi comuni di investimento. Insieme ai dati Forex, Crypto e Fondamentali, tutti accessibili tramite la loro API REST. Offrono un abbonamento gratuito o premium che dipende dal numero di chiamate API richieste. I loro pacchetti premium vanno da 49,99$ a 249,99$ al mese. Sebbene la maggior parte dei loro dati siano liberamente accessibili con limitazioni API di 5 chiamate al minuto, negli ultimi anni alcuni set di dati hanno iniziato a essere classificati come premium. I set di dati considerati premium sono variabili e soggetti a modifiche nel tempo. Ad esempio, nel 2022 i dati azionari di fine giornata (EOD) aggiustati sono disponibili solo per i pacchetti premium. Tuttavia, nel 2023, questi dati saranno nuovamente disponibili gratuitamente e i dati EOD giornalieri non aggiustati saranno premium.
Per impostazione predefinita, le chiamate API di AlphaVantage scaricano gli ultimi 100 punti dati, ma possiamo scaricare tutti i dati storici disponibili specificando il parametro outputsize=full. Possiamo comunque filtrare in base a un intervallo di date dopo il download. AlphaVantage fornisce i dati dei titoli azionari per un periodo di oltre 20 anni, mentre il Forex e Crypto hanno periodi variabili. I dati di USD:GBP sono disponibili al 2003 mentre i dati USD:BTC coprono gli ultimi 3 anni. Inoltre sono disponibili 5 anni di dati fondamentali.
In questo articolo esaminiamo come accedere ai dati storici tramite l’API di AlphaVantage e come inserirli in un DataFrame Pandas per ulteriori analisi. Creiamo quindi un grafico a candele OHLC tramite la libreria Plotly.
Questo articolo fa parte della serie di tutorial relativi all’analisi di Dati Finanziari per il Trading Algoritmico.
Per implementare il codice di questo articolo abbiamo bisogno di:
- Python 3.8
- Pandas 1.4
- Plotly 5.6
- Requests 2.27
Il REST API di AlphaVantage
Per usare AlphaVantage dobbiamo sottoscrivere l’abbonamento gratuito (o premium) e ottenere una chiave API. Dopo aver ottenuto la chiave, possiamo iniziare a scaricare i dati dalla loro API tramite una richiesta get. Iniziamo importando le librerie necessarie; requests per effettuare una chiamata API e Pandas per creare un DataFrame con i dati delle serie temporali scaricate.
import pandas as pd
import requests
request e aggiungiamo la chiave API all’URL. In questo caso vogliamo richiede i dati OHLCV giornalieri aggiustati (function=TIME_SERIES_DAILY_ADJUSTED) per AAPL (symbol=AAPL) per tutto lo storico disponibile (outputsize=full). Salviamo l’output JSON in una variabile av_json usando il metodo JSON integrato di Python. Ricordiamo di aggiungere la chiave API alla fine dell’istruzione request (apikey=YOUR_API_KEY).
av_response = requests.get('https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol=AAPL&outputsize=full&apikey=YOUR_API_KEY')
av_json = av_response.json()
Possiamo vedere cosa è stato restituito dalla chiamata API semplicemente stampando la variabile av_json con print(av_json).

Il formato JSON
JSON è diventato uno dei modi più popolari per trasferire dati dalle API, tuttavia non è completamente standardizzato. I dati vengono comunemente trasferiti come liste di dizionari, ma esistono sempre delle eccezioni. Nel caso di AlphaVantage la chiamata API restituisce dizionari nidificati. La variabile av_json è un dizionario di dizionari. Questo modello è abbastanza comune, quindi vale la pena dedicare del tempo a capire dove sono archiviati i dati e come accedervi. Il dizionario esterno ha due chiavi:Meta Data e Time Series (Daily). I valori di entrambe queste chiavi sono anche dizionari. La prima coppia chiave-valore rappresenta i metadati per il download, la seconda rappresenta i dati della serie temporale. I dati che ci interessano si trovano all’interno della seconda coppia chiave:valore. Questo è un dizionario dove le chiavi sono le date e i valori sono un altro dizionario contenente i punti dati OHLCV. Quindi i dati sono archiviati in una struttura di dizionari nidificati a tre livelli. Possiamo accedere al dizionario delle serie temporali tramite la chiave Time Series (Daily).
access_ts = av_json["Time Series (Daily)"]
print(access_ts)
Otteniamo un dizionario dove i valori sono dizionari di serie temporali.

pd.DataFrame otteniamo un DataFrame con date come colonne e i prezzi OHLCV come righe.
av_aapl = pd.DataFrame(av_json["Time Series (Daily)"])
print(av_aapl.head())
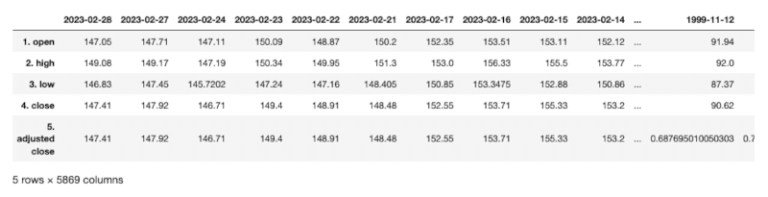
Possiamo trasporre questi dati tramite il metodo DataFrame.transpose in modo da scambiare le colonne e le righe. Dato che le chiamate ripetute di trasposizione capovolgono i dati avanti e indietro, è sempre opportuno creare una nuova variabile ed assegnarle il dataframe trasposto.
av_aapl_transpose = av_aapl.T
print(av_aapl_transpose.head())
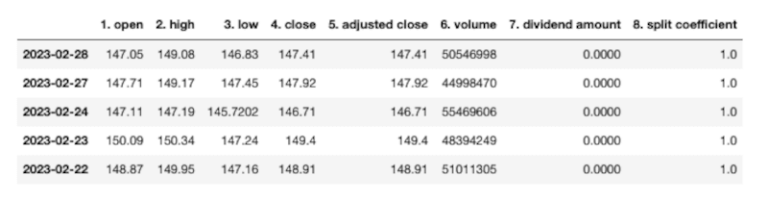
Dobbiamo quindi assicurarci che l’indice del dataframe sia un oggetto datetime.
av_aapl_transpose.index = pd.to_datetime(av_aapl_transpose.index)
E ordiniamo l’indice in modo che sia in ordine crescente
av_aapl_transpose = av_aapl_transpose.sort_index()
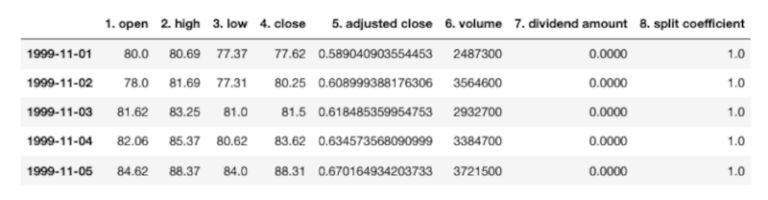
Il formato CSV
Oltre al formato JSON possiamo anche scaricare file CSV da AlphaVantage e leggerli direttamente in un Pandas DataFrame. In questo caso il metodo pd.read_csv assegna anche la colonna dell’indice e analizza direttamente le date riducendo al minimo il lavoro di codifica aggiuntivo per formattare i dati. Dobbiamo ricordarci di aggiungere la chiave API alla fine dell’istruzione di request (apikey=YOUR_API_KEY).
csv_url = 'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol=AAPL&outputsize=full&datatype=csv&apikey=av_key'
aapl_csv = pd.read_csv(csv_url, index_col='timestamp', parse_dates=True, infer_datetime_format=True)
print(aapl_csv.head())
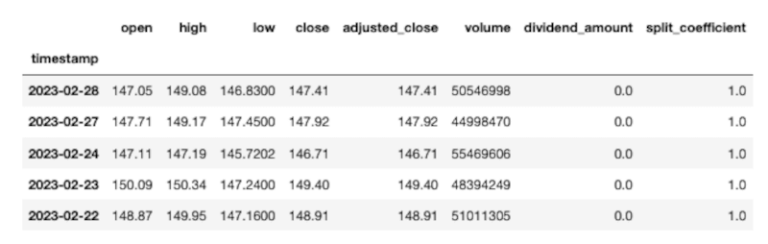
Ora che abbiamo esaminato come inserire un singolo titolo in un DataFrame per ulteriori analisi. estendiamo il metodo per esaminare più titoli azioniari. Nel successivo esempio scarichiamo i dati storici completi per 5 ETF disponibili su AlphaVantage. Tieni presente che per gli utenti con abbonamento free le chiamate API sono limitate a 5 al minuto. Pertanto è necessario assicurarsi che la chiamata API non sia ripetuta. In questo modo puoi estrarre i dati ed eseguire le tue analisi senza chiamare ripetutamente l’API.
Grafico multicandela degli ETF settoriali
Per prima cosa creiamo una lista di ticker che vogliamo analizzare. Se non sei sicuro del ticker del tuo titolo, puoi utilizzare l’endpoint dell’API per la ricerca dei simboli . Tieni presente che questo utilizzerà una delle chiamate API disponibili nel minuto!
etf_symbols_list = ['SPY', 'XLF', 'XLE', 'XLU', 'XLP']
Memorizziamo i dati in un dizionario dove le chiavi sono i ticker azionari e i valori sono i DataFrames OHLCV. Ricordiamo di aggiungere la vera chiave API alla fine dell’istruzione di request (apikey=YOUR_API_KEY).
etf_data = {}
for symbol in etf_symbols_list:
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={symbol}&outputsize=full&datatype=csv&apikey=YOUR_API_KEY'
etf_data[symbol] = pd.read_csv(url, index_col='timestamp', parse_dates=True, infer_datetime_format=True)
Possiamo scorrere le chiavi nel dizionario per eseguire ulteriori azioni di formattazione sui nostri DataFrames. In questo caso ordiniamo l’indice e aggiungiamo una colonna per calcolare la media mobile.
for etf in etf_data.keys():
etf_data[etf] = etf_data[etf].sort_index()
etf_data[etf]['MA5'] = etf_data[etf]['adjusted_close'].rolling(5).mean()
Vediamo quindi come creare un grafico candlestick con Plotly e Alphavantage che mostri i dati OHLC come candele per ciascuno dei cinque ETF. Usiamo la libreria Plotly come abbiamo fatto negli articoli precedenti ma estendiamo il grafico per includere le sottofigure. Dato che abbiamo scaricato lo storico completo da AlphaVantage, il primo passo è creare una maschera per filtrare i dati nell’intervallo di dati desiderato. Creiamo un nuovo dizionario di DataFrames in modo che la nostra cronologia completa sottostante sia ancora accessibile. Usiamo la libreria datetime.
from datetime import datetime as dt
start = dt(2023, 1, 24)
end = dt(2023, 2, 24)
etf_data_mask = {}
for etf in etf_data.keys():
mask = (etf_data[etf].index >= start) & (etf_data[etf].index <= end)
etf_data_mask[etf] = etf_data[etf].loc[mask]
Possiamo esaminare i dati filtrati per ciascun ticker come segue:
print(etf_data_mask['SPY'])
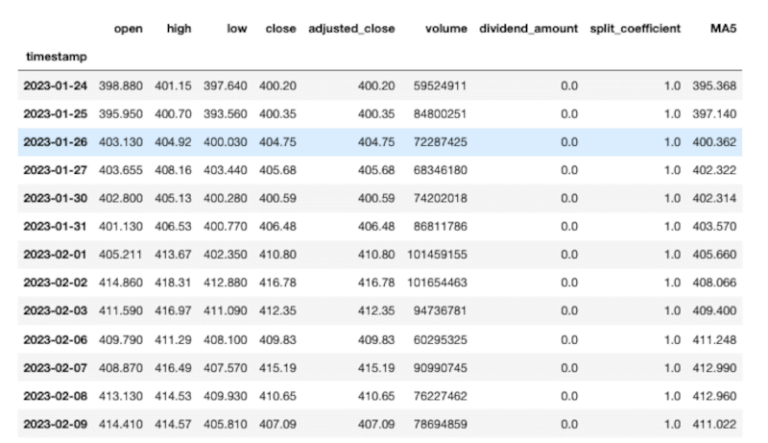
make_subplots permette di specificare la forma della sottotrama tramite gli argomenti chiave rows e cols. Abbiamo bisogno di 3 righe e 2 colonne. Per garantire che il primo grafico sia più grande possiamo usare la parola chiave specs. In questo modo possiamo definire determinati parametri per ciascuna sottotrama tramite un dizionario. L’argomento della parola chiave specs è un array con le stesse dimensioni della sottotrama. Dato che prevediamo 3 righe e 2 colonne, il nostro array vuoto appare come segue:
specs = [[{}, {}],
[{}, {}],
[{}, {}]]
Il dizionario permette di specificare il parametro colspan per ciascuno dei grafici. Dato che il valore predefinito è 1, dobbiamo solo specificare il colspan per la prima sottotrama. Impostiamo anche la seconda colonna della prima riga su “none” in modo da non visualizzare nessun grafico. Inoltre, per visualizzare il volume sullo stesso grafico delle candele, impostiamo il valore di secondary_y a True.
La funzione make_subplots prevede la parola chiave subplot_titles che permette di impostare un titolo per ciascuna delle nostre sottotrame. Qui usiamo la lista etf_symbols_list che abbiamo creato durante il download dei dati. Possiamo anche impostare le etichette per gli assi x e y. Iniziamo importando make_subplots e plotly.graph_objects
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(
rows=3, cols=2,
specs=[[{"colspan": 2, 'secondary_y': True}, None],
[{'secondary_y': True}, {'secondary_y': True},],
[{'secondary_y': True}, {'secondary_y': True},]],
subplot_titles=(etf_symbols_list),
x_title="Date",
y_title="OHLC"
)
fig.show()
Invece di usare etf_symbols_list per iterare i ticker, creiamo una nuova lista plot_symbols con sei elementi. Anche se stiamo tracciando cinque ETF, tecnicamente ci sono sei sottotrame disponibili. Dobbiamo regolare l’iterazione per avere sei elementi in modo da garantire che la sottotrama nella prima posizione non visualizzi i dati di due ETF. Dobbiamo tenere conto di questo quando definiamo la posizione della riga e della colonna.
Enumeriamo attraverso la lista plot_symbols per definire il numero intero di riga e colonna. Questo è un metodo comune per definire la posizione delle sottotrame, quindi vale la pena approfondirlo. Dove le sottotrame sono tracciate da sinistra a destra attraverso le colonne, l’assegnazione delle sottotrame segue uno schema per cui il numero di riga si ripete n volte, dove n è il numero di colonne. Nel nostro caso il numero di riga per ogni trama è 1, 1, 2, 2, 3, 3. Questo modello può essere ottenuto eseguendo la divisione intera. i // num_cols fornisce il numero di riga desiderato per ciascuna sottotrama. Per le colonne lo schema è la sequenza ripetuta dei numeri di colonna, nel nostro caso 1, 2, 1, 2, 1, 2. Ciò può essere ottenuto utilizzando l’operatore modulo. i % num_rows fornisce la posizione della colonna.
Poiché plotly non è indicizzato a zero, dobbiamo semplicemente aggiungere 1 al calcolo per ottenere il valore corretto per righe e colonne. Per accogliere la nostra sottofigura più grande usiamo anche un if statement per rendere row e col uguali a 1 nella seconda iterazione del ciclo. Ora possiamo aggiungere ciascun grafico candlestick in un ciclo con le posizioni definite correttamente. Infine usiamo fig.update_layout per rimuovere la legenda, impostare il testo e la posizione del titolo e disattivare il rangeslider
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(
rows=3, cols=2,
specs=[[{"colspan": 2, 'secondary_y': True}, None],
[{'secondary_y': True}, {'secondary_y': True}],
[{'secondary_y': True}, {'secondary_y': True}]],
subplot_titles=(etf_symbols_list),
x_title="Date",
y_title="OHLC"
)
plot_symbols = ['SPY', 'SPY', 'XLF', 'XLE', 'XLU', 'XLP']
for i, etf in enumerate(plot_symbols):
if i == 1:
row = 1
col = 1
else:
row = (i//2)+1
col = (i%2)+1
fig.add_trace(
go.Candlestick(
x=etf_data_mask[etf].index,
open=etf_data_mask[etf]['open'],
high=etf_data_mask[etf]['high'],
low=etf_data_mask[etf]['low'],
close=etf_data_mask[etf]['adjusted_close'],
name="OHLC"
),
row=row, col=col
)
fig.update_layout(
showlegend=False,
title_text="OHLC data for SPY, XLF, XLE, XLU and XLP",
title_xref="paper",
title_x=0.5,
title_xanchor="center")
fig.update_xaxes(rangeslider_visible=False)
fig.show()
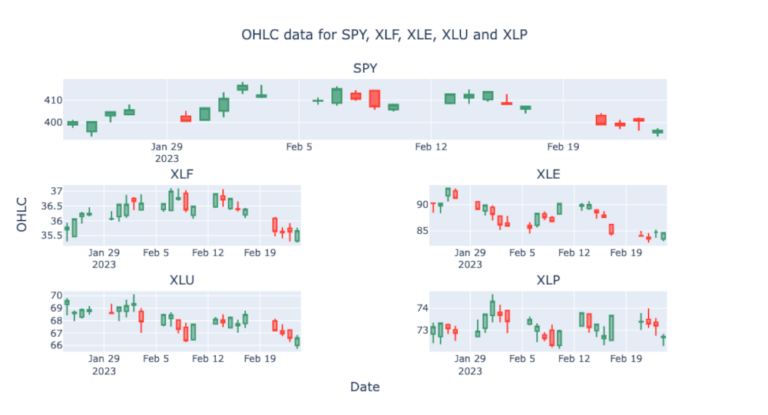
Abbiamo effettuato la maggior parte del lavoro. non ci resta che aggiungere il volume a ciascun grafico con un asse y secondario e un grafico a dispersione per la media mobile.
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(
rows=3, cols=2,
specs=[[{"colspan": 2, 'secondary_y': True}, None],
[{'secondary_y': True}, {'secondary_y': True}],
[{'secondary_y': True}, {'secondary_y': True}]],
subplot_titles=(etf_symbols_list),
x_title="Date",
y_title="OHLC"
)
plot_symbols = ['SPY', 'SPY', 'XLF', 'XLE', 'XLU', 'XLP']
for i, etf in enumerate(plot_symbols):
if i == 1:
row = 1
col = 1
else:
row = (i//2)+1
col = (i%2)+1
fig.add_trace(
go.Candlestick(
x=etf_data_mask[etf].index,
open=etf_data_mask[etf]['open'],
high=etf_data_mask[etf]['high'],
low=etf_data_mask[etf]['low'],
close=etf_data_mask[etf]['adjusted_close'],
name="OHLC"
),
row=row, col=col
)
fig.add_trace(
go.Bar(
x=etf_data_mask[etf].index,
y=etf_data_mask[etf]['volume'],
opacity=0.1,
marker_color='blue',
name="volume"
),
row=row, col=col, secondary_y=True,
)
fig.add_trace(
go.Scatter(
x=etf_data_mask[etf].index,
y=etf_data_mask[etf].MA5,
line=dict(color='black', width=1),
name="5 day MA",
yaxis="y2"
),
row=row, col=col, secondary_y=False,
)
fig.layout.yaxis2.showgrid=False
fig.update_layout(
showlegend=False,
title_text="OHLC data for SPY, XLF, XLE, XLU and XLP",
title_xref="paper",
title_x=0.5,
title_xanchor="center")
fig.update_xaxes(rangeslider_visible=False)
fig.show()
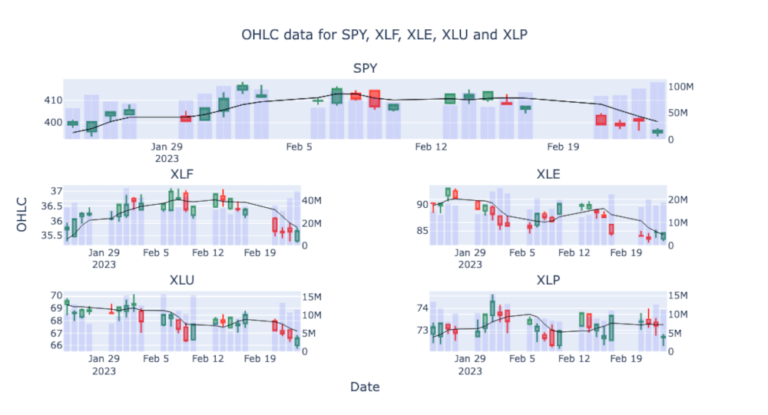
Abbiamo visto un primo esempio per creare un grafico candlestick con Plotly e AlphaVantage, fornendo una panoramica sull’accesso ai dati AlphaVantage tramite l’API e sulla creazione di grafici più complessi. Per completezza, vediamo anche alcuni degli altri dati che possono essere ottenuti da AlphaVantage e come trasformare i dati in DataFrames per ulteriori analisi.
I dati di AlphaVantage per il Forex
AlphaVantage offre dati OHLC per 157 valute fiat. Con un abbonamento premium i dati OHLC possono essere ottenuti sulle frequenze Intraday (1 minuto, 5 minuti, 15 minuti, 30 minuti e 60 minuti). Gli abbonamenti free possono scaricare dati giornalieri, settimanali e mensili. La dimensione di output completa restituisce gli ultimi 5000 punti temporali (candele o barre) della serie temporale. AlphaVantage attualmente non offre dati sulle quotazioni (prezzo bid e ask), ma offre dati sui tassi di cambio.
Di seguito vediamo un esempio di chiamata API per ottenere i dati OHLC storici completi per le serie temporali giornaliere GBP:USD. Dobbiamo ricordarci di aggiungere la chiave API alla fine dell’istruzione request (apikey=YOUR_API_KEY).
rResponse = requests.get(
'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=GBP&to_symbol=USD&outputsize=full&apikey=YOUR_API_KEY'
)
gbp_usd_j = rResponse.json()
gbp_usd = pd.DataFrame(gbp_usd_j["Time Series FX (Daily)"])
gbp_usd_transpose = gbp_usd.T
gbp_usd_transpose.tail()

Dati di AlphaVantage per le
cryptovalute
Alphavantage offre dati su 575 valute digitali, in tutte le valute fisiche. Il dato è simile a quello già discusso per il Forex. Gli utenti Premium possono accedere ai dati OHLC intraday che includono anche il volume. Gli abbonamenti gratuiti possono accedere ai dati giornalieri, settimanali e mensili. La dimensione di output completa per le valute digitali è di 1000 punti temporali di dati nella serie temporale.
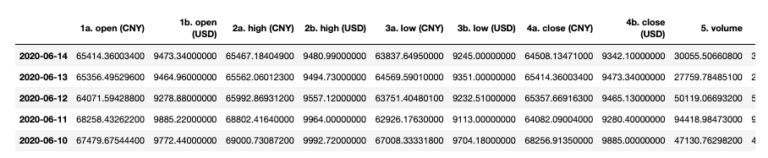
Di seguito è riportato un esempio di chiamata API per Bitcoin(BTC) e Yuan cinese(CNY). Tieni presente che ti vengono forniti anche i dati OHLCV in USD.
rResponse = requests.get(
'https://www.alphavantage.co/query?function=DIGITAL_CURRENCY_DAILY&symbol=BTC&market=CNY&apikey=YOUR_API_KEY'
)
btc_usd_j = rResponse.json()
btc_usd = pd.DataFrame(btc_usd_j["Time Series (Digital Currency Daily)"])
btc_usd_transpose = btc_usd.T
btc_usd_transpose.tail()
I dati di AlphaVantage per i
fondamentali
AlphaVantage offre anche dati fondamentali su una varietà di intervalli di tempo. Ciò include informazioni sul delising della società. Le informazioni sul delisting dei titoli sono molto importanti per il backtesting. Per eseguire un backtest storico di una strategia su un indice e garantire risultati accurati, è necessario rappresentare le società corrette nell’indice per tutto il periodo di tempo coperto dal backtest.
Se dobbiamo eseguire un backtest di 20 anni sui titoli attuali dell’S&P500, otterresti un risultato molto favorevole. Non perché la tua strategia di trading sia fantastica, ma perché hai introdotto il bias di sopravvivenza. Le società attualmente incluse nell’S&P500 non sono le stesse di 20 anni fa. L’S&P500 è un elenco delle 500 migliori aziende. La tua strategia viene eseguita su aziende che sono cresciute nel corso degli ultimi 20 anni. Queste informazioni non sarebbero state disponibili 20 anni fa. La tua strategia dovrebbe essere eseguita sui dati delle società presenti nell’S&P500 in qualsiasi momento.
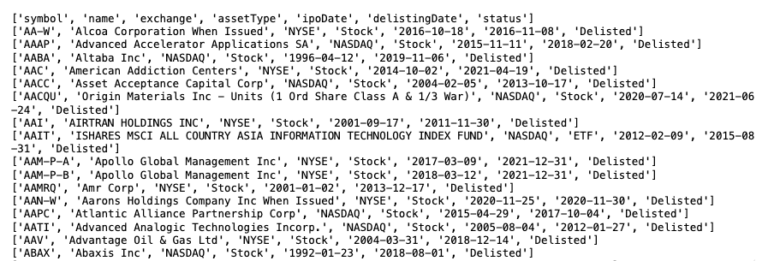
Di seguito mostriamo come accedere ai dati CSV dei delist.
import csv
CSV_URL = 'https://www.alphavantage.co/query?function=LISTING_STATUS&date=2022-02-10&state=delisted&apikey=YOUR_API_KEY'
with requests.Session() as s:
download = s.get(CSV_URL)
decoded_content = download.content.decode('utf-8')
cr = csv.reader(decoded_content.splitlines(), delimiter=',')
my_list = list(cr)
for row in my_list:
print(row)
AlphaVantage offre anche dati sugli indicatori economici e tecnici, nonché materie prime e alcune analisi del sentiment. Tutti i dati sono disponibili tramite la loro API. L’accesso ad alcuni set di dati richiede un abbonamento premium, che (come discusso in precedenza) sono soggetti a modifiche. Come con tutti i fornitori di dati gratuiti, è bene utilizzare i dati per acquisire familiarità con metodi e prototipazione. Tuttavia, non è adatto per il trading live. Come accennato negli articoli precedenti, la maggior parte dei fornitori di dati gratuiti prevede termini e condizioni che ne impediscono l’uso.
In questo articolo abbiamo descritto come creare un grafico candlestick con Plotly e AlphaVantage e fa parte della serie di tutorial relativi all’analisi di Dati Finanziari per il Trading Algoritmico.