In questo articolo introduciamo uno dei problemi più importanti e delicati del machine learning, cioè la selezione del modello e il compromesso bias-varianza . Quest’ultimo è uno dei problemi più cruciali nella realizzazione di redditizie strategie di trading basate su tecniche di machine learning.
La selezione del modello si riferisce alla capacità di valutare le prestazioni di diversi modelli di machine learning al fine di scegliere il migliore.
Il compromesso bias-varianza è una proprietà specifica di tutti i modelli di machine learning (supervisionati), che impone un compromesso tra la “flessibilità” del modello e il comportamento su dati che non ha mai visto (out of sample). Quest’ultimo è noto come prestazione di generalizzazione dei modelli .
Inizieremo descrivendo l’importanza della selezione del modello e successivamente vedremo qualitativamente il compromesso bias-varianza. Concluderemo l’articolo derivando matematicamente il compromesso bias-varianza e discuteremo le misure per minimizzare i problemi che si introducono.
In questo articolo prendiamo in considerazione modelli di regressione supervisionati . Cioè, modelli che vengono addestrati su una serie di dati di addestramento etichettati e producono una risposta quantitativa . Un esempio di ciò potrebbe essere il tentativo di prevedere i futuri prezzi delle azioni sulla base di altri fattori come i prezzi passati, i tassi di interesse o i tassi di cambio.
Questo è in contrasto con un modello di risposta categoriale o binario come nel caso della classificazione supervisionata . Un esempio di classificazione è l’assegnazione (o almeno il tentativo) di un argomento a un documento di testo, da un insieme finito di argomenti. Le situazioni di bias-varianza e selezione del modello per la classificazione sono estremamente simili al modello di regressione e richiedono semplicemente una modifica per gestire i diversi modi in cui vengono misurati gli errori e le prestazioni. Discuteremo queste modifiche in un ultimo articolo.
Nota: se si desidera saperne di più sulla notazione del modello di base che useremo in questo articolo, vale la pena leggere l’ articolo sulle basi del machine learning statistico .
Modelli di machine learning
Come per la maggior parte delle nostre discussioni sul machine learning, il modello di base è il seguente:
\(\begin{eqnarray} Y = f (X) + \epsilon \end{eqnarray}\)
Questo afferma che il vettore di risposta, \(Y\), è una funzione (potenzialmente non lineare), \(f\), del vettore predittore, \(X\), con un insieme di termini di errore con distribuzione normale che hanno media pari a 0 e deviazione standard pari a 1.
Cosa significa in pratica?
Ad esempio, il vettore \(X\) potrebbe rappresentare un insieme di prezzi finanziari ritardati. Potrebbe anche rappresentare i tassi di interesse, i prezzi dei derivati, i prezzi degli immobili, le frequenze delle parole in un documento o qualsiasi altro fattore che consideriamo utile per fare una previsione .
Il vettore \(Y\) può essere singolo o multi-valore. Il primo caso potrebbe semplicemente essere il prezzo delle azioni di domani, nel secondo caso potrebbe essere i prezzi giornalieri previsionali della prossima settimana.
\(f\) rappresenta la visione della sottostante relazione tra \(Y\) e \(X\). Questa potrebbe essere lineare , nel qual caso possiamo stimare \(f\) tramite un modello di regressione lineare. Potrebbe essere non lineare , in questo caso possiamo stimare \(f\) con una Support Vector Machine o, per esempio, un metodo basato su spline.
I termini di errore \(\epsilon\) rappresentano tutti i fattori che influenzano \(Y\) che non abbiamo preso in considerazione con la nostra funzione \(f\). Sono essenzialmente le componenti “sconosciute” del modello di previsione. Solitamente si presumere che questi hanno una distribuzione normale, con media pari a 0 e deviazione standard pari a 1.
In questo articolo descriviamo come misurare le prestazioni di una stima per la funzione (sconosciuta) \(f\). Tale stima utilizza la notazione “hat”. Quindi, \(\hat {f} \) può essere letto come “la stima di \(f\)”.
Inoltre descriviamo l’effetto sulle prestazioni del modello man mano che lo rendiamo più flessibile . La flessibilità descrive la capacità di aumentare i gradi di libertà disponibili per il modello al fine di “adattarsi” ai dati di addestramento. Vedremo che la relazione tra flessibilità ed errore di prestazione è non lineare e quindi dobbiamo essere estremamente attenti nella scelta del modello “migliore”.
Da notare che non esiste mai un modello “migliore” per la totalità delle statistiche e del machine learning. Diversi modelli hanno diversi punti di forza e di debolezza. Un modello può funzionare molto bene su un set di dati, ma può funzionare male su un altro. La sfida nel machine learning statistico è scegliere il modello “migliore” per il problema in questione, a seconda dei dati disponibili.
Selezione del modello
Quando si cerca di trovare il “migliore” metodo di machine learning statistico, abbiamo bisogno di alcuni mezzi per caratterizzare le prestazioni dei vari modelli.
Per ottenere ciò, dobbiamo confrontare i valori noti della relazione sottostante con quelli previsti da un modello stimato .
Ad esempio, se stiamo provando a prevedere i prezzi delle azioni di domani, allora desideriamo valutare quanto le previsioni dei nostri modelli siano vicine al valore reale, in un particolare giorno.
Ciò motiva il concetto di una funzione di perdita , che confronta quantitativamente la differenza tra i valori reali con i valori previsti.
Supponiamo di aver creato una stima \(\hat{f}\) della relazione sottostante \(f\). \(\hat {f}\) potrebbe essere, per esempio, una regressione lineare o un modello di random forest. \(\ hat {f}\) sarà stato addestrato su un particolare set di dati, \(\tau \), che contiene coppie predittore-risposta. Se ci sono \(N\) coppie, \( \tau \) è ricavato come:
\(\begin{eqnarray} \tau = \{(X_1, Y_1), …, (X_N, Y_N) \} \end{eqnarray}\)
\(X_i\) rappresentano i fattori di previsione, che potrebbero essere i prezzi precedenti ritardati per una serie o altri fattori, come menzionato sopra. \(Y_i\) potrebbero essere le previsioni per i nostri prezzi delle azioni nel periodo successivo. In questo caso, \(N\) rappresenta il numero di giorni di dati che abbiamo a disposizione.
La funzione di perdita è indicata con \(L (Y, \hat{f} (X))\). Il suo compito è confrontare le previsioni fatte da \(\hat {f}\) su valori specifici di $ X $ con i loro veri valori dati da \(Y\). Una scelta comune per \(L\) è l’ errore assoluto
\(\begin{eqnarray} L (Y, \hat{f} (X)) = | Y – \hat{f} (X) | \end{eqnarray}\)
Un’altra scelta popolare è l’errore quadratico
\(\begin{eqnarray} L (Y, \hat{f} (X)) = (Y – \hat{f} (X)) ^2 \end{eqnarray}\)
Notare che entrambe le scelte della funzione di perdita non sono negative. Quindi la “migliore” perdita per un modello è zero, cioè non c’è differenza tra la previsione e il valore reale.
Errore di addestramento contro errore di prova
Ora che abbiamo una funzione di perdita, abbiamo bisogno di un modo per aggregare le varie differenze tra i valori veri e quelli previsti. Un modo per farlo è definire l’Errore al quadrato medio (MSE), che è semplicemente la media, o il valore atteso, della perdita al quadrato:
\(\begin{eqnarray} MSE: = \frac {1} {N} \sum ^ {N} _ {i = 1} (Y_i – \hat {f} (X_i)) ^ 2 \end{eqnarray}\)
La definizione afferma semplicemente che l’errore quadratico medio corrisponde alla media di tutte le differenze al quadrato tra i valori veri \(Y_i\) e i valori previsti \(\hat {f} (X_i) \). Un MSE più piccolo significa che la stima è più accurata.
È importante rendersi conto che questo valore MSE viene calcolato utilizzando solo i dati di addestramento . Cioè, viene calcolato utilizzando solo i dati su cui è stato costruito il modello. Quindi, in realtà è noto come training MSE.
In pratica, questo valore ci interessa poco. Quello che bisogna veramente valutare è la bontà del modello nel prevedere i corretti valori per un set di dati mai visti in precedenza.
Ad esempio, non siamo realmente interessati alla qualità di previsione del modello per i prezzi delle azioni del giorno successivo nel passato, ci interessa solo come può prevedere i prezzi delle azioni dei giorni successivi in futuro. Questa quantificazione delle prestazioni di un modello è nota come prestazioni di generalizzazione. È quello che ci interessa veramente.
Matematicamente, se abbiamo un nuovo valore di previsione \(X_0\) e una risposta vera \(Y_0\), allora desideriamo prendere l’aspettativa su tutti questi nuovi valori per ottenere il test MSE:
\(\begin{eqnarray} \text {Test MSE}: = \mathbb {E} \left [(Y_0 – \hat{f} (X_0)) ^2 \right] \end{eqnarray}\)
Dove l’aspettativa viene presa attraverso tutte le nuove coppie di predittore-risposta invisibili \((X_0, Y_0)\).
Il nostro obiettivo è selezionare il modello per cui il test MSE è più basso tra tutti gli altri modelli possibili.
Purtroppo è difficile calcolare il test MSE! Questo perché spesso ci troviamo in una situazione in cui non abbiamo a disposizione dati di test .
In generale, nei domini di machine learning questo può essere abbastanza comune. Nel trading quantitativo ci troviamo (di solito) in un ambiente “ricco di dati” e quindi possiamo conservare alcuni dei nostri dati per l’addestramento e altri per i test. In articoli futuri discuteremo della convalida incrociata , che è uno dei mezzi per utilizzare sottoinsiemi dei dati di addestramento al fine di stimare il test MSE.
Una domanda pertinente da porsi in questa fase è “Perché non possiamo semplicemente utilizzare il modello con la training MSE più basso?”. La risposta è che non siamo in grado di utilizzare questo approccio perché non vi è alcuna garanzia che il modello con il MSE di training MSE più basso sarà anche il modello con il test MSE più basso. Per quale motivo? La risposta consiste in una particolare proprietà dei metodi di apprendimento automatico statistico nota come compromesso bias-varianza .
Il compromesso bias-varianza
Consideriamo una situazione leggermente artificiosa in cui conosciamo la “vera” relazione tra \(Y\) e \(X\), che affermerò è data da una funzione sinusoidale, \(f = \sin\), tale che \(Y = f (X ) = \sin (X)\). Da notare che in realtà non conosceremo mai il sottostante \(f\), motivo per cui lo stiamo stimando in prima analisi!
Per questa situazione artificiosa abbiamo creato una serie di punti di allenamento, \(\tau\), dati da \(Y_i = \sin (X_i) + \epsilon_i\), dove \(\epsilon_i\) sono tratti da una distribuzione normale standard (media di zero, deviazione standard uguale a uno). Questo può essere visto nella Figura 1. La curva nera è la “vera” funzione \(f\), limitata all’intervallo \([0, 2 \ pi]\), mentre i punti cerchiati rappresentano i valori dei dati simulati \(Y_i\).
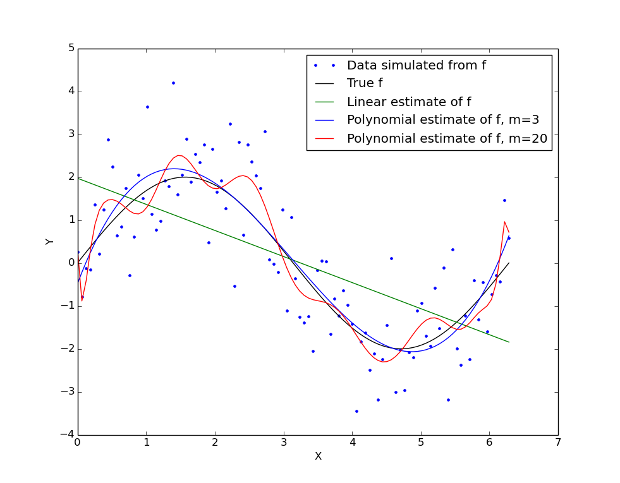
Ora possiamo provare ad adattare alcuni diversi modelli a questi dati di addestramento. Il primo modello, dato dalla linea verde, è una regressione lineare dotata di stima dei minimi quadrati ordinari. Il secondo modello, dato dalla linea blu, è un modello polinomiale con grado \(m = 3\). Il terzo modello, dato dalla curva rossa, è un polinomio di grado superiore con grado \(m = 20\). Tra ciascuno dei modelli abbiamo variato la flessibilità , cioè i gradi di libertà (DoF). Il modello lineare è il meno flessibile con solo due DoF. Il modello più flessibile è il polinomio di ordine \(m = 20\). Si può vedere che il polinomio di ordine \(m = 3\) è l’apparente più vicino adattamento alla relazione sinusoidale sottostante.
Per ciascuno di questi modelli possiamo calcolare il training MSE . Si può vedere nella Figura 2 che il training MSE (dato dalla curva verde) diminuisce monotonicamente all’aumentare della flessibilità del modello. Ciò ha senso, poiché l’adattamento polinomiale può diventare flessibile quanto necessario per ridurre al minimo la differenza tra i suoi valori e quelli dei dati sinusoidali.
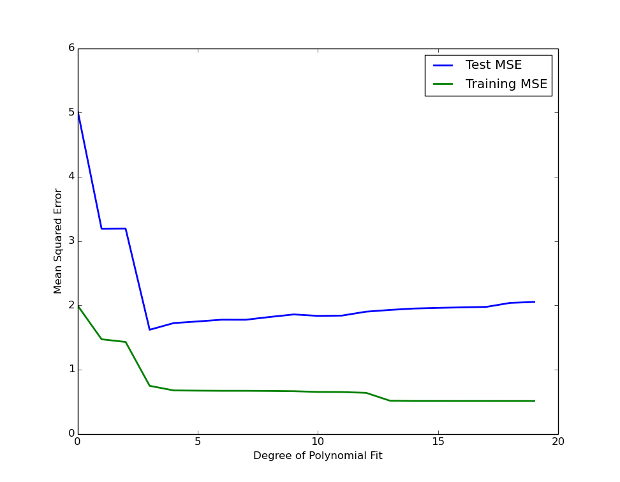
Tuttavia, se tracciamo il test MSE (dato dalla curva blu) la situazione è molto diversa. Il test MSE inizialmente diminuisce man mano che aumentiamo la flessibilità del modello, ma alla fine ricomincia ad aumentare dopo aver introdotto molta flessibilità. Questo avviene perché prevedendo un modello estremamente flessibile, permettiamo che si adatti ai “modelli” nei dati di addestramento.
Tuttavia, non appena introduciamo nuovi dati mai visti nel set di test, il modello non riesce a generalizzare in modo corretto perché questi “modelli” sono solo artefatti casuali dei dati di addestramento e non sono una proprietà sottostante della vera forma sinusoidale. Siamo in una situazione di overfitting .
In effetti, questa proprietà di un test MSE “a forma di U” in funzione della flessibilità del modello è una proprietà intrinseca dei modelli statistici di machine learning, nota come compromesso bias-varianza .
Si può dimostrare (vedere di seguito nella sezione Spiegazione matematica) che il test MSE previsto, in cui l’aspettativa viene presa in molti set di addestramento, è dato da:
\(\begin{eqnarray} \mathbb{E}(Y_0 – \hat{f}(X_0))^2 = \text{Var}(\hat{f}(X_0)) + \left[ \text{Bias} \hat{f}(X_0)\right]^2 + \text{Var}(\epsilon) \end{eqnarray}\)
Il primo termine a destra è la varianza della stima in molti set di addestramento. Determina la deviazione della stima del modello medio quando vengono provati diversi dati di addestramento. In particolare, un modello con un’elevata varianza suggerisce che sia troppo adattato ai dati di allenamento.
Il termine medio è il bias al quadrato , che caratterizza la differenza tra le medie della stima e i valori reali. Un modello con un alto bias non sta catturando il comportamento base della “vera” forma funzionale. Si può immaginare una situazione dove si usa una regressione lineare per modellare una curva sinusoidale (come sopra). Non importa quanto bene il modello si “adatti” ai dati, non catturerà mai la non linearità inerente a una curva sinusoidale.
Il termine finale è noto come errore irriducibile . È il limite inferiore minimo per il test MSE. Dato che abbiamo accesso solo ai punti dati di addestramento (inclusa la casualità associata ai valori \(\epsilon\)) non è mai possibile ottenere un adattamento “più accurato” di quello che offre la varianza dei residui.
In generale, con l’aumentare della flessibilità, vediamo un aumento della varianza e una diminuzione del bias. Tuttavia è il relativo tasso di variazione tra questi due fattori che determina se ile test MSE atteso aumenta o diminuisce.
Man mano che la flessibilità aumenta, il bias tenderà a diminuire rapidamente (più velocemente di quanto la varianza possa aumentare) e quindi vediamo un calo nel test MSE. Tuttavia, man mano che la flessibilità aumenta ulteriormente, vi è meno riduzione del bias (perché la flessibilità del modello può adattarsi facilmente ai dati di addestramento) mentre la varianza aumenta rapidamente, a causa del sovradimensionamento del modello.
L’obiettivo finale del machine learning è cercare di ridurre al minimo il test MSE previsto , ovvero scegliere un modello di machine learning statistico che abbia contemporaneamente una bassa varianza e un basso bias .
Al fine di stimare il test MSE previsto, possiamo utilizzare tecniche come la convalida incrociata . Tali tecniche saranno oggetto di articoli futuri.
Se desideri ottenere una definizione matematicamente più precisa del compromesso bias-varianza, puoi leggere la sezione successiva.
Una spiegazione matematica
Abbiamo finora delineato qualitativamente i problemi che circondano la flessibilità, il bias e la varianza del modello. Nel seguente riquadro eseguiremo una scomposizione matematica dell’errore di previsione atteso per una particolare stima del modello, \(\hat {f} (X) \) con il vettore di previsione \( X = x_0 \) utilizzando l’ultima delle nostre funzioni di perdita, la perdita di errore al quadrato:
La definizione della perdita dell’errore quadratico, nel punto di previsione \(X_0\) $, è data da:
\(\begin{eqnarray} \text{Err} (X_0) = \mathbb{E} \left[ \left( Y – \hat{f}(X_0) \right)^2 | X = X_0 \right] \end{eqnarray}\)
Tuttavia, possiamo espandere l’aspettativa sul lato destro in tre termini:
\(\begin{eqnarray} \text{Err} (X_0) = \sigma^{2}_{\epsilon} + \left[ \mathbb{E} \hat{f} (X_0) – f(X_0)\right]^2 + \mathbb{E} \left[ \hat{f}(X_0) – \mathbb{E} \hat{f}(X_0) \right]^2 \end{eqnarray}\)
Il primo termine sulla RHS è noto come errore irriducibile . È il limite inferiore del possibile errore di previsione.
Il termine medio è il bias al quadrato e rappresenta la differenza tra valore medio di tutte le previsioni a \(X_0\), in tutti i possibili set di addestramento, e il vero valore medio della funzione sottostante a \(X_0\).
Questo può essere visto come l’errore introdotto dal modello nel non rappresentare il comportamento base della vera funzione. Ad esempio, utilizzando un modello lineare quando il fenomeno è intrinsecamente non lineare.
Il terzo termine è noto come varianza . Caratterizza l’errore introdotto quando il modello diventa più flessibile e quindi più sensibile alle variazioni tra diversi set di addestramento, \(\tau\).
\(\begin{eqnarray} \text{Err} (X_0) &=& \sigma^{2}_{\epsilon} + \text{Bias}^2 + \text{Var} (\hat{f}(X_0))\\ &=& \text{Irreducible Error} + \text{Bias}^2 + \text{Variance} \end{eqnarray}\)
È importante ricordare che \(\sigma^{2} _ \epsilon\) rappresenta un limite inferiore assoluto dell’errore di previsione. Mentre l’errore di addestramento atteso può essere ridotto monotonicamente a zero (semplicemente aumentando la flessibilità del modello), l’errore di previsione atteso sarà sempre almeno l’errore irriducibile, anche se il bias al quadrato e la varianza sono entrambi zero.
Nei prossimi articoli analizzeremo gli strumenti per stimare il test MSE previsto, tramite tecniche di ricampionamento come la convalida incrociata . Inoltre vedremo come le cose cambiano quando si considerano problemi di classificazione.