
In questo articolo consideriamo una strategia di trading costruita sulla base del motore di predizione descritto nei precedenti articoli sul tema machine learning e forecasting.
Proveremo a tradare le predizioni effettuate dal foracaster del mercato azionario.
Questo algoritmo si basa per la maggior parte sul software che abbiamo già sviluppato utilizzando il backtesting vettoriale e descritto in questo articolo. Esso viene rivesto ed adattato per essere innestato nel nuovo motore di backtesting basato sugli eventi in modo da avere una maggiore accuratezza nell’esecuzione delle operazioni e calcolo delle performance.
La Strategia di Forecasting
In questa strategia si vuol prevedere l’andamento dello SPY, l’ETF che replica il valore dell’S&P 500. In definitiva, vogliamo rispondere alla domanda se un semplice algoritmo di previsione che utilizza dati sui prezzi ritardati e con una leggera performance predittiva, possa offrire vantaggi rispetto a una strategia “buy & hold”.
Le regole per questa strategia sono le seguenti:
- Adattare un modello di previsione a un sottoinsieme di dati dell’S&P500. In questa strategia utilizziamo l’ Analisi Discriminante Quadratica , ma si potrebbe utilizzare anche una regressione logistica, una macchina vettoriale di supporto o una foresta casuale.
- Utilizza due ritardi precedenti sui rendimenti dei prezzi di chiusura aggiustati come predittore dei rendimenti di domani. Se i rendimenti sono previsti positivi, allora si va long. Se i rendimenti sono previsti negativi, si esce dalla posizione. Non prenderemo in considerazione la vendita allo scoperto per questa particolare strategia.
Implementazione
Per questa strategia si prevede di creare il snp_forecast.py ed importare le seguenti librerie:
# snp_forecast.py
import datetime
import pandas as pd
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
from strategy.strategy import Strategy
from event.event import SignalEvent
from backtest.backtest import Backtest
from data.data import HistoricCSVDataHandler
from execution.execution import SimulatedExecutionHandler
from portfolio.portfolio import Portfolio
from model.forecast import create_lagged_series
Abbiamo importato Pandas e Scikit-Learn per eseguire la procedura di adattamento per il modello di classificazione supervisionato. Abbiamo anche importato le classi necessarie dal motore di backtesting basato su eventi. Infine, abbiamo importato la funzione create_lagged_series, che abbiamo utilizzato nell’articolo di introduzione al forecasting delle serie temporali capitolo Previsione.
Il passaggio successivo consiste nel creare SPYDailyForecastStrategy come sottoclasse della classe base astratta Strategy. Poiché “codificheremo” i parametri della strategia direttamente nella classe, per semplicità, gli unici parametri necessari per il costruttore __init__ sono il gestore dati delle barre e la coda degli eventi.
Impostiamo le date di inzio / fine / test del modello di previsione e poi diciamo alla classe che siamo fuori dal mercato (self.long_market = False). Infine, impostiamo self.model come modello addestrato dalla funzione create_symbol_forecast_model, come segue:
# snp_forecast.py
class SPYDailyForecastStrategy(Strategy):
"""
Strategia previsionale dell'S&P500. Usa un Quadratic Discriminant
Analyser per prevedere i rendimenti per uno determinato sottoperiodo
e quindi genera segnali long e di uscita basati sulla previsione.
"""
def __init__(self, bars, events):
self.bars = bars
self.symbol_list = self.bars.symbol_list
self.events = events
self.datetime_now = datetime.datetime.utcnow()
self.model_start_date = datetime.datetime(2001,1,10)
self.model_end_date = datetime.datetime(2005,12,31)
self.model_start_test_date = datetime.datetime(2005,1,1)
self.long_market = False
self.short_market = False
self.bar_index = 0
self.model = self.create_symbol_forecast_model()
create_symbol_forecast_model. Essenzialmente si richiama la funzione create_lagged_series, che produce un DataFrame pandas con cinque diveri ritardi di rendimenti giornalieri per ogni predittore corrente.
Consideriamo quindi solo i due ritardi più recenti. Questo perché stiamo introducendo una regola di modellazione che consiste nell’ipotizzare che il potere predittivo dei ritardi precedenti è probabilmente minimo.
In questa fase creiamo i dati di addestramento e test, l’ultimo dei quali può essere utilizzato per testare il nostro modello, se lo si desidera. Si è scelto di non produrre dati di test, poiché abbiamo già addestrato il modello nel precedente articolo. Infine adattiamo i dati di addestramento al
Quadratic Discriminant Analyzer e quindi restituiamo il modello.
Si noti che possiamo facilmente sostituire il modello con, ad esempio, una foresta casuale, una macchina vettoriale di supporto o una regressione logistica. Tutto quello che dobbiamo fare è importare la libreria corretta da Scikit-Learn e sostituire semplicemente la riga model = QDA():
# snp_forecast.py
def create_symbol_forecast_model(self):
# Creazione delle serie ritardate dell'indice S&P500
# del mercato azionario US
snpret = create_lagged_series(
self.symbol_list[0], self.model_start_date,
self.model_end_date, lags=5
)
# Uso i rendimenti dei due giorni precedenti come valore
# previsionale, con direzione come risposta
X = snpret[["Lag1", "Lag2"]]
y = snpret["Direction"]
# Creazione dei set di dati per il training e il test
start_test = self.model_start_test_date
X_train = X[X.index < start_test]
X_test = X[X.index >= start_test]
y_train = y[y.index < start_test]
y_test = y[y.index >= start_test]
model = QDA()
model.fit(X_train, y_train)
return model
prepare_signals della classe base Strategy. Per prima cosa calcoliamo alcuni parametri utilizzati dal nostro oggetto SignalEvent e quindi generiamo un set di segnali solo se abbiamo ricevuto un oggetto MarketEvent (un controllo base di integrità).
Attendiamo che siano trascorse cinque barre (ovvero cinque giorni per questa strategia!) e quindi otteniamo i valori di rendimenti ritardati. Quindi racchiudiamo questi valori in una serie pandas in modo da garantire il corretto funzionamento del metodo di previsione del modello. Quindi calcoliamo una previsione, che si manifesta come un valore +1 o -1.
Se la previsione è un +1 e non siamo già long sul mercato, creiamo un
SignalEvent per andare long e far sapere al sistema che siamo entrati a mercato. Se la previsione è -1 e siamo long sul mercato, allora si esce dal mercato:
# snp_forecast.py
def calculate_signals(self, event):
"""
Calcolo di SignalEvents in base ai dati di mercato.
"""
sym = self.symbol_list[0]
dt = self.datetime_now
if event.type == 'MARKET':
self.bar_index += 1
if self.bar_index > 5:
lags = self.bars.get_latest_bars_values(
self.symbol_list[0], "returns", N=3
)
pred_series = pd.Series({
'Lag1': lags[1] * 100.0,
'Lag2': lags[2] * 100.0
})
pred = self.model.predict(pred_series)
if pred > 0 and not self.long_market:
self.long_market = True
signal = SignalEvent(1, sym, dt, 'LONG', 1.0)
self.events.put(signal)
if pred < 0 and self.long_market:
self.long_market = False
signal = SignalEvent(1, sym, dt, 'EXIT', 1.0)
self.events.put(signal)
Backtest ed si esegue il test richiamando il metodo simulate_trading:
# snp_forecast.py
if __name__ == "__main__":
csv_dir = '/path/to/your/csv/file' # CHANGE THIS!
symbol_list = ['SPY']
initial_capital = 100000.0
heartbeat = 0.0
start_date = datetime.datetime(2006,1,3)
backtest = Backtest(
csv_dir, symbol_list, initial_capital, heartbeat,
start_date, HistoricCSVDataHandler, SimulatedExecutionHandler,
Portfolio, SPYDailyForecastStrategy
)
backtest.simulate_trading()
..
..
2209
2210
Creating summary stats...
Creating equity curve...
SPY cash commission total returns equity_curve \
datetime
2014-09-29 19754 90563.3 349.7 110317.3 -0.000326 1.103173
2014-09-30 19702 90563.3 349.7 110265.3 -0.000471 1.102653
2014-10-01 19435 90563.3 349.7 109998.3 -0.002421 1.099983
2014-10-02 19438 90563.3 349.7 110001.3 0.000027 1.100013
2014-10-03 19652 90563.3 349.7 110215.3 0.001945 1.102153
2014-10-06 19629 90563.3 349.7 110192.3 -0.000209 1.101923
2014-10-07 19326 90563.3 349.7 109889.3 -0.002750 1.098893
2014-10-08 19664 90563.3 349.7 110227.3 0.003076 1.102273
2014-10-09 19274 90563.3 349.7 109837.3 -0.003538 1.098373
2014-10-09 0 109836.0 351.0 109836.0 -0.000012 1.098360
drawdown
datetime
2014-09-29 0.003340
2014-09-30 0.003860
2014-10-01 0.006530
2014-10-02 0.006500
2014-10-03 0.004360
2014-10-06 0.004590
2014-10-07 0.007620
2014-10-08 0.004240
2014-10-09 0.008140
2014-10-09 0.008153
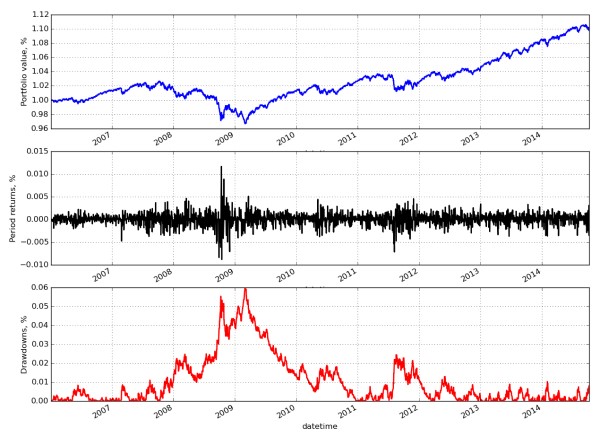
[(’Total Return’, ’9.84%’),
(’Sharpe Ratio’, ’0.54’),
(’Max Drawdown’, ’5.99%’),
(’Drawdown Duration’, ’811’)]
Signals: 270
Orders: 270
Fills: 270
Quindi non abbiamo effettivamente ottenuto un vantaggio da questa strategia predittiva una volta inclusi i costi di transazione. In particolare, ho voluto includere questo esempio perché utilizza un’implementazione realistica “end to end” di tale strategia che tiene conto dei costi di transazione conservativi e realistici. Come si può vedere non è facile fare una previsione predittiva su dati giornalieri che produca buone prestazioni!
Codice Completo
Per il codice completo riportato in questo articolo, utilizzando il modulo di backtesting event-driven DataBacktest si può consultare il seguente repository di github:
https://github.com/datatrading-info/DataBacktest



