Nel precedente articolo sui modelli di Markov nascosti abbiamo descritto la loro applicazione per indicizzare i dati sui rendimenti come meccanismo per scoprire i “regimi di mercato” latenti. Abbiamo analizzato i rendimenti dell’S&P500 usando le librerie statistiche Python. Abbiamo rilevato che i periodi di diversa volatilità, usando sia modelli a due stati che a tre stati.
In questo articolo, usiamo il modello Hidden Markov all’interno del framework DataTrader come filtro del regime di mercato per la gestione del rischio. In altre parole la logica prevede di non effettuare operazioni quando sono previsti regimi di volatilità più elevati. In questo modo si vuole eliminare le operazioni non redditizie e, possibilmente, rimuovere la volatilità dalla strategia aumentando così il suo Sharpe ratio .
Per raggiungere tale obbiettivo abbiamo effettuato alcune piccole modifiche al codice di DataTrader, disponibile nella sua pagina Github .
L’identificazione del regime di mercato è abbinato a una semplicistica strategia di trend-following a breve termine, basata su semplici regole di crossover della media mobile. La strategia in sé è relativamente irrilevante ai fini di questo articolo, poiché la maggior parte della discussione si concentra sull’implementazione della logica di gestione del rischio.
DataTrader è scritto in Python, quindi ai fini di questo articolo usiamo una libreria Python che ci fornisce un’implementazione del Modello Markov Nascosto “pronto all’uso”. La libreria che usiamo è chiamata hmmlearn.
Rilevamento del regime con modelli Markov nascosti
Se non hai familiarità con i modelli Markov nascosti e/o non sei a conoscenza di come possono essere utilizzati come strumento di gestione del rischio, vale la pena dare un’occhiata ai seguenti articoli della serie:
- Modelli nascosti di Markov – Introduzione
- Modelli Markov nascosti per il rilevamento del regime utilizzando R
Il primo descrive i concetti matematici e statistici alla base del modello, mentre il secondo articolo utilizza python per adattare un HMM ai rendimenti dell’S&P500.
I modelli di Markov nascosti sono un tipo di modello stocastico dello spazio degli stati. Presuppone l’esistenza di stati “nascosti” o “latenti” che non sono direttamente osservabili. Questi stati nascosti hanno un’influenza sui valori che sono osservabili, noti come le osservazioni. Uno degli obiettivi del modello è accertare lo stato attuale dall’insieme delle osservazioni note.
Nel trading quantitativo questo problema si traduce nell’avere regimi di mercato “nascosti” o “latenti”, come ila modifica delle normative o i periodi di elevata volatilità. In questo caso le osservazioni sono i rendimenti di un particolare insieme di dati del mercato finanziario. I rendimenti sono indirettamente influenzati dai regimi nascosti del mercato. L’adattamento di un modello di Markov nascosto ai dati sui rendimenti consente di “prevedere” i nuovi stati di regime, che possono essere utilizzati come meccanismo di filtro per la gestione del rischio nel trading.
La strategia di trading
La strategia di trading per questo articolo è estremamente semplice e viene utilizzata perché può essere ben compresa. L’aspetto su cui vogliamo focalizzarci è la gestione del rischio.
La strategia trend following a breve termine è il classico crossover delle medie mobile. Le regole sono semplici:
- Ad ogni barra calcola le medie mobili semplici (SMA) a 10 e 30 giorni
- Se la SMA a 10 giorni supera la SMA a 30 giorni e la strategia non è a mercato, allora andiamo long
- Se la SMA a 30 giorni supera la SMA a 10 giorni e la strategia è a mercato, si chiude la posizione
Questa non è una strategia particolarmente efficace con questi parametri, in particolare sui prezzi dell’indice S&P500. Non è molto differente rispetto a un buy-and-hold dell’ETF SPY per lo stesso periodo.
Tuttavia, se combinato con un filtro di trading di gestione del rischio, diventa più efficace a causa della possibilità di eliminare i trade che si verificano in periodi altamente volatili, quando le strategie di trend-following possono perdere denaro.
Il filtro di gestione del rischio si basa sull’addestramento di un modello Markov nascosto sui dati S&P500 dal 29 gennaio 1993 (i primi dati disponibili per SPY su Yahoo Finance) fino al 31 dicembre 2004. Questo modello viene quindi serializzato (tramite Python pickle ) e usato nella sottoclasse RiskManager di DataTrader.
Il gestore del rischio controlla, per ogni operazione inviata, se lo stato attuale è un regime di bassa o alta volatilità. Se la volatilità è bassa, tutte le operazioni long sono ammesse e portate a termine. Se la volatilità è elevata, qualsiasi operazione aperta viene chiusa quando si riceve il segnale di uscita, mentre qualsiasi nuova potenziale operazione long viene annullata prima di poter essere eseguita.
In questo modo si ottiene, potenziale l’effetto desiderato, cioè eliminare i trade trend-following in periodi di alta volatilità quando è più probabile che perdano denaro a causa dell’errata identificazione del “trend”.
Il backtest di questa strategia viene effettuato dal 1 gennaio 2005 al 31 dicembre 2014, senza riaddestrare il modello Hidden Markov durante il periodo. Questo significa che l’HMM viene usato out-of-sample e non sui dati di addestramento nel campione.
Dati
Per testare questa strategia è necessario disporre dei dati OHLCV per i prezzi giornalieri dell’ETF con ticker SPY, sia il periodo di addestramento dell’HMM che il periodo del backtest:
| Ticker | Nome | Periodo | Collegamento |
|---|---|---|---|
| SPY | SPDR S&P 500 ETF | 29 gennaio 1993 – 31 dicembre 2014 | Yahoo Finanza |
Se si desidera replicare i risultati, questi dati dovranno essere inseriti nella directory specificata dal file delle impostazioni di DataTrader
Implementazione Python
Calcolo dei rendimenti con DataTrader
Per effettuare le previsioni del regime usando il modello Hidden Markov è necessario calcolare e memorizzare i rendimenti dei prezzi di chiusura dell’ETF SPY. Ad oggi sono stati memorizzati solo i prezzi. La posizione naturale in cui archiviare i rendimenti è all’interno della sottoclasse di
PriceHandler. Quindi abbiamo aggiunto questa funzionalità nel framework DataTrader.
È stato un aggiornamento relativamente semplice, composto da due principali modifiche. In primo luogo abbiamo aggiunto un flag booleano calc_adj_returns all’inizializzazione della classe. Se è impostato a True, si calcola e memorizza i rendimenti. Il flag è impostato a False. per default, in questo modo si riduce l’impatto sull’resto del codice client.
La seconda modifica consiste nel sovrascrive il metodo “virtuale” _store_event presente all’interno della classe AbstractBarPriceHandler con il seguente codice presente nella classe YahooDailyCsvBarPriceHandler.
Il codice controlla se calc_adj_returns è uguale a True. Memorizza gli attuali e precedenti prezzi di chiusura tramite il PriceParser, calcola i rendimenti percentuali e poi li aggiunge alla lista adj_close_returns. Questo elenco viene successivamente richiamato dal RegimeHMMRiskManager per prevedere lo stato attuale del regime:
def _store_event(self, event):
"""
Memorizza il prezzo di chiusura e di chiusura aggiustata per ogni evento
"""
ticker = event.ticker
# Se il flag calc_adj_returns è True, calcola e memorizza
# in un elenco tutta la lista dei rendimenti percentuali
# del prezzo di chiusura aggiustata
# TODO: Aumentare la velocità
if self.calc_adj_returns:
prev_adj_close = self.tickers[ticker]["adj_close"] / float(PriceParser.PRICE_MULTIPLIER)
cur_adj_close = event.adj_close_price / float(PriceParser.PRICE_MULTIPLIER)
self.tickers[ticker][
"adj_close_ret"
] = cur_adj_close / prev_adj_close - 1.0
self.adj_close_returns.append(self.tickers[ticker]["adj_close_ret"])
self.tickers[ticker]["close"] = event.close_price
self.tickers[ticker]["adj_close"] = event.adj_close_price
self.tickers[ticker]["timestamp"] = event.time
Questa modifica è disponibile nell’ultima versione di DataTrader, che (come sempre) può essere trovata alla pagina Github.
Implementazione del rilevamento del regime
L’attenzione sarà ora rivolta all’implementazione del filtro del regime e alla strategia di trend following a breve termine che sono usate per eseguire il backtest.
Per l’esecuzione di questa strategia sono necessari quattro differenti file. Il listato completo di ciascuno file sono riportati alla fine di questo articolo. Questo consente di replicare direttamente i risultati per coloro che desiderano implementare un metodo simile.
Il primo file comprende l’adattamento di un modello gaussiano di Markov nascosto per un ampio periodo dei rendimenti dell’S&P500. Il secondo file contiene la logica per effettuare il trend-following di breve termine. Il terzo file fornisce il filtro di regime di mercato tramite un oggetto di gestione del rischio. Il file finale lega insieme tutti questi moduli in un a procedura di backtest.
Addestrare il modello Markov nascosto
Prima di creare un filtro per rilevare il regime del mercato è necessario adattare il modello di Markov nascosto a un dataset dei rendimenti. A tale scopo usiamo la libreria Python hmmlearn. L’API è estremamente semplice, semplifica l’adattamento e la memorizzazione del modello per un uso successivo.
Il primo compito è importare le librerie necessarie. pickle è necessario per serializzare il modello da utilizzare nel gestore del rischio di rilevamento del regime. warnings viene utilizzato per eliminare gli avvisi di deprecazione generati da Scikit-Learn, tramite le chiamate API da hmmlearn. GaussianHMM è usato da hmmlearn e costituisce la base del modello. Matplotlib e Seaborn sono importati per visualizzare i grafici degli stati nascosti all’interno del campione, necessari per un “controllo di integrità” sul comportamento dei modelli:
# regime_hmm_train.py
import datetime
import pickle
import warnings
from hmmlearn.hmm import GaussianHMM
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
import numpy as np
import pandas as pd
import seaborn as sns
La funzione obtain_prices_df legge il file CSV dei dati SPY scaricati da Yahoo Finance e importa i dati in un Pandas DataFrame. Quindi calcola i rendimenti percentuali dei prezzi di chiusura rettificati e tronca la data di fine al periodo di addestramento desiderato. Il calcolo dei rendimenti percentuali introduce valori NaN nel DataFrame, che vengono quindi eliminati:
def obtain_prices_df(csv_filepath, end_date):
"""
Legge i prezzi dal file CSV e li carica in un Dataframe,
filtra per data di fine e calcola i rendimenti percentuali.
"""
df = pd.read_csv(
csv_filepath, header=0,
names=[
"Date", "Open", "High", "Low",
"Close", "Volume", "Adj Close"
],
index_col="Date", parse_dates=True
)
df["Returns"] = df["Adj Close"].pct_change()
df = df[:end_date.strftime("%Y-%m-%d")]
df.dropna(inplace=True)
return df
La seguente funzione, plot_in_sample_hidden_states, non è strettamente necessaria ai fini dell’addestramento. Abbiamo modificato il file tutorial, presente nella documentazione di hmmlearn.
Il codice prende i dati del modello e il dataframe dei prezzi e crea un grafico per ogni stato nascosto generato dal modello. Ogni grafico mostra il prezzo di chiusura mascherato da quel particolare stato/regime nascosto. Questo è utile per verificare se l’HMM sta producendo stati “sani”:
def plot_in_sample_hidden_states(hmm_model, df):
"""
Traccia il grafico dei prezzi di chiusura rettificati
mascherati dagli stati nascosti nel campione come
meccanismo per comprendere i regimi di mercato.
"""
# Array con gli stati nascosti previsti
hidden_states = hmm_model.predict(df["Returns"])
# Crea il grafico formattato correttamente
fig, axs = plt.subplots(
hmm_model.n_components,
sharex=True, sharey=True
)
colours = cm.rainbow(
np.linspace(0, 1, hmm_model.n_components)
)
for i, (ax, colour) in enumerate(zip(axs, colours)):
mask = hidden_states == i
ax.plot_date(
df.index[mask],
df["Adj Close"][mask],
".", linestyle='none',
c=colour
)
ax.set_title("Hidden State #%s" % i)
ax.xaxis.set_major_locator(YearLocator())
ax.xaxis.set_minor_locator(MonthLocator())
ax.grid(True)
plt.show()
La seguente figura riporta l’output di questa specifica funzione:
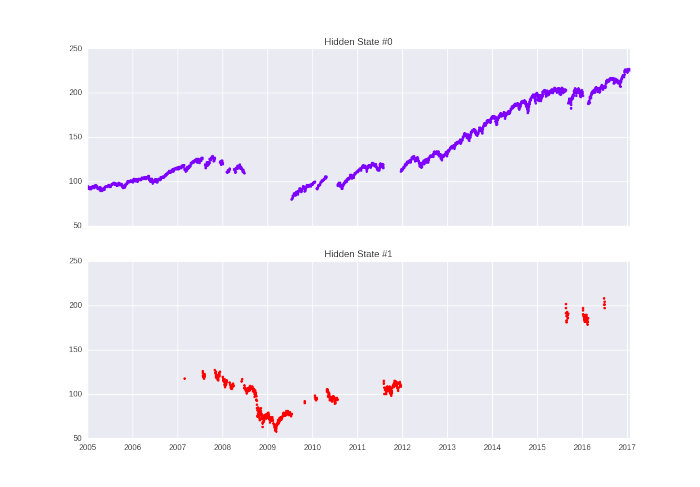
Notiamo come il rilevamento del regime cattura in gran parte periodi di “tendenza” e periodi altamente volatili. In particolare la maggior parte del 2008 si trova nel Hidden State #1.
Questo script è legato insieme nella funzione __main__. In primo luogo, tutti gli avvisi vengono ignorati. A rigor di logica questo non l’approccio corretto, ma in questo caso ci sono molti avvisi di deprecazione generati da Scikit-Learn che oscurano l’output desiderato dello script.
Successivamente apriamo il file CSV e si crea la variabile rets tramite il comando np.column_stack perché hmmlearn richiede una matrice di oggetti Series di pandas, nonostante si tratti di un modello univariato (agisce solo sui rendimenti). A tale scopo dobbiamo usare le funzionalità messe a disposizione dalla libreria NumPy.
L’oggetto GaussianHMM richiede di specificare il numero di stati tramite il parametro n_components. In questo articolo usiamo due stati, ma si può facilmente testare lo stesso algoritmo con tre stati. Inoltre usiamo una matrice di covarianza completa, anziché una versione diagonale e usiamo il parametro n_iter per definire il numero di iterazioni per l’algoritmo Expectation-Maximisation.
Addestriamo il modello e visualizziamo l’output dell’algoritmo e il grafico degli Hidden State dei prezzi di chiusura rettificati. Infine il modello è serializzato in pickle_path, pronto per essere usato nel gestore del rischio per rilevamento del regime:
if __name__ == "__main__":
# Nasconde gli avvisi di deprecazione per sklearn
warnings.filterwarnings("ignore")
# Crea il dataframe SPY dal file CSV di Yahoo Finance e
# formatta correttamente i rendimente per l'uso nell'HMM
csv_filepath = "/path/to/your/data/SPY.csv"
pickle_path = "/path/to/your/model/hmm_model_spy.pkl"
end_date = datetime.datetime(2004, 12, 31)
spy = obtain_prices_df(csv_filepath, end_date)
rets = np.column_stack([spy["Returns"]])
# Crea il Gaussian Hidden markov Model e lo adatta ai
# dati dei rendimenti di SPY, visualizzando il punteggio
hmm_model = GaussianHMM(
n_components=2, covariance_type="full", n_iter=1000
).fit(rets)
print("Model Score:", hmm_model.score(rets))
# Grafico dei valori di chiusura degli stati nascosti del campione
plot_in_sample_hidden_states(hmm_model, spy)
print("Pickling HMM model...")
pickle.dump(hmm_model, open(pickle_path, "wb"))
print("...HMM model pickled.")
Strategia Trend Following a breve termine
La fase successiva del processo consiste nel creare la classeStrategy che implementa la logica trend following a breve termine, filtrata successivamente dal modulo RiskManager.
Come per tutte le strategie sviluppate all’interno di DataTrader è necessario importare alcune classi specifiche, tra cui PriceParser, SignalEvente la classe base AbstractStrategy. Questa strategia è simile a molte descritte negli articoli precedenti quindi non descriviamo i singoli passaggi di importazione delle librerie:
# regime_hmm_strategy.py
from collections import deque
import numpy as np
from datatrader.price_parser import PriceParser
from datatrader.event import SignalEvent, EventType
from datatrader.strategy.base import AbstractStrategy
In realtà la sottoclasse MovingAverageCrossStrategysottoclasse è già stata usata in uno degli esempi precedenti. Tuttavia la replichiamo per completezza. La strategia utilizza due code a doppia estremità, disponibili nel modulo deque, per fornire le finestre scorrevoli sui dati sui prezzi. Questo serve per calcolare le medie mobili semplici che formano la logica del trend-following a breve termine:
class MovingAverageCrossStrategy(AbstractStrategy):
"""
Requisiti:
tickers - La lista dei simboli dei ticker
events_queue - Il manager della coda degli eventi
short_window - Periodo di lookback per la media mobile breve
long_window - Periodo di lookback per la media mobile lunga
"""
def __init__(
self, tickers,
events_queue, base_quantity,
short_window=10, long_window=30
):
self.tickers = tickers
self.events_queue = events_queue
self.base_quantity = base_quantity
self.short_window = short_window
self.long_window = long_window
self.bars = 0
self.invested = False
self.sw_bars = deque(maxlen=self.short_window)
self.lw_bars = deque(maxlen=self.long_window)
Nel framework di backtesting event-driven DataTrader tutte le sottoclassi derivate da AbstractStrategy prevedono l’uso del metodo calculate_signals per generare oggetti SignalEvent. Per la nostra strategia il metodo verifica innanzitutto se l’evento è una barra OHLCV. Ad esempio, potrebbe essere un SentimentEvent (come in altre strategie ) e quindi è necessario prevedere un controllo. Aggiungiamo i prezzi più recenti alle code delle finestre mobili in modo da aggiornare le SMA.
Se ci sono abbastanza barre per eseguire le medie mobili, queste sono entrambe calcolate. Una volta che questi valori sono presenti, eseguiamo le regole di trading sopra descritte. Se la SMA della finestra breve supera la SMA della finestra lunga e la strategia non è già a mercato, generiamo una posizione long di base_quantity azioni. Se la SMA della finestra lunga supera la SMA della finestra breve la posizione viene chiusa se siamo a mercato:
def calculate_signals(self, event):
# Applica SMA al primo ticker
ticker = self.tickers[0]
if event.type == EventType.BAR and event.ticker == ticker:
# Aggiunge l'ultimo prezzo di chiusura ai dati
# delle finestre corta e lunga
price = event.adj_close_price / PriceParser.PRICE_MULTIPLIER
self.lw_bars.append(price)
if self.bars > self.long_window - self.short_window:
self.sw_bars.append(price)
# Sono presenti abbastanza barre per il trading
if self.bars > self.long_window:
# Calcola le medie mobili semplici
short_sma = np.mean(self.sw_bars)
long_sma = np.mean(self.lw_bars)
# Segnali di trading basati sulla media mobile incrociata
if short_sma > long_sma and not self.invested:
print("LONG: %s" % event.time)
signal = SignalEvent(ticker, "BOT", self.base_quantity)
self.events_queue.put(signal)
self.invested = True
elif short_sma < long_sma and self.invested:
print("SHORT: %s" % event.time)
signal = SignalEvent(ticker, "SLD", self.base_quantity)
self.events_queue.put(signal)
self.invested = False
self.bars += 1
Rilevamento del regime nel RiskManager
In questo articolo vediamo come creare un oggetto come sottoclasse di AbstractRiskManager. E’ il primo utilizzo importante della gestione del rischio applicato separatamente a una strategia di trading fino ad oggi sul sito datatrading.info. Come indicato sopra, l’obiettivo di questo oggetto è quello di filtrare le operazioni trend-following a breve termine quando si trovano in un regime ad alta volatilità non desiderato.
Tutte le sottoclassi di tipo RiskManager richiedono l’accesso ad un OrderEvent perchè devono poter di eliminare, modificare o creare ordini a seconda dei vincoli di rischio del portafoglio:
# regime_hmm_risk_manager.py
import numpy as np
from datatrader.event import OrderEvent
from datatrader.price_parser import PriceParser
from datatrader.risk_manager.base import AbstractRiskManager
Creiamo la classe RegimeHMMRiskManager che richiede semplicemente la lettura del file del modello HMM deserializzato. Inoltre dobbiamo tenere traccia se la strategia è “investita” o meno, poiché l’oggetto Strategy non è a conoscenza se i suoi segnali sono stati effettivamente eseguiti:
class RegimeHMMRiskManager(AbstractRiskManager):
"""
Utilizza un modello Hidden Markov precedentemente adattato
come meccanismo di rilevamento del regime. Il gestore del
rischio ignora gli ordini che si verificano durante
un regime non desiderato.
Ciò spiega anche il fatto che un'operazione può essere
a cavallo di due regimi separati. Se un ordine di chiusura
viene ricevuto nel regime non desiderato e l'ordine è aperto,
verrà chiuso, ma non verranno generati nuovi ordini fino
al raggiungimento del regime desiderato.
"""
def __init__(self, hmm_model):
self.hmm_model = hmm_model
self.invested = False
Creiamo un metodo helper, determine_regime, che usa l’oggetto price_handler e l’evento l’ sized_order per ottenere l’elenco completo dei rendimenti dei prezzi di chiusura calcolati da DataTrader (per i dettagli vedere il codice nella sezione precedente). Quindi usiamo il metodo predict dell’oggetto GaussianHMM per produrre una serie di stati di regime previsti. Prendiamo il valore più recente e lo usiamo come “stato nascosto” o regime corrente:
def determine_regime(self, price_handler, sized_order):
"""
Determina il probabile regime effettuando una previsione sui rendimenti
dei prezzi di chiusura nell'oggetto PriceHandler e quindi prende
il valore intero finale come "stato del regime nascosto"
"""
returns = np.column_stack(
[np.array(price_handler.adj_close_returns)]
)
hidden_state = self.hmm_model.predict(returns)[-1]
return hidden_state
Il metodo refine_orders è obbligatori in tutte le sottoclassi derivate da AbstractRiskManager. In questo caso eseguiamo il metodo determine_regime per determinare lo stato del regime. Creiamo infine il corretto oggetto l’ OrderEvent, che sarà modificato successivamente:
def refine_orders(self, portfolio, sized_order):
"""
Utilizza il modello di Markov nascosto con i rendimenti percentuali
per determinare il regime corrente, 0 per desiderabile o 1 per
indesiderabile. Ingressi Long seguiti solo in regime 0, operazioni
di chiusura sono consentite in regime 1.
"""
# Determinare il regime previsto HMM come un intero
# uguale a 0 (desiderabile) o 1 (indesiderabile)
price_handler = portfolio.price_handler
regime = self.determine_regime(
price_handler, sized_order
)
action = sized_order.action
# Crea l'evento dell'ordine, indipendentemente dal regime. Sarà
# restituito solo se le condizioni corrette sono soddisfatte.
order_event = OrderEvent(
sized_order.ticker,
sized_order.action,
sized_order.quantity
)
..
..
Nella seconda metà del metodo implementiamo la logica per la gestione del rischio a seguito del rilevamento del regime. Consiste in un blocco condizionale che verifica quale stato di regime è stato individuato.
Se siamo in uno stato di bassa volatilità #0, controlliamo se l’ordine è di tipo “BOT” o “SLD”. Se si tratta di un ordine “BOT” (long), restituisce un OrderEvent d aggiorna lo stato “invested”. Se è un ordine “SLD” (chiudi) allora chiude la posizione se è aperta, altrimenti annulla l’ordine.
Inoltre se prevediamo un regime sia lo stato di alta volatilità #1, verifichiamo quale ordine è stato creato. Non vogliamo posizioni long in questo regime di mercato. Permettiamo invece di chiudere una posizione solo se è stata precedentemente aperta una posizione long, altrimenti la annulla.
Questo ha l’effetto di non generare mai una nuova posizione long quando si è in regime #1. Tuttavia, una posizione long precedentemente aperta può essere chiusa nel regime n. 1.
Un approccio alternativo potrebbe essere quello di chiudere immediatamente qualsiasi posizione long aperta entrando nel regime #1. Questo è lasciato come esercizio per il lettore!
..
..
# Se abbiamo un regime desiderato, permettiamo gli ordini di acquisto e di
# vendita normalmente per una strategia di trend following di solo lungo
if regime == 0:
if action == "BOT":
self.invested = True
return [order_event]
elif action == "SLD":
if self.invested == True:
self.invested = False
return [order_event]
else:
return []
# Se abbiamo un regime non desiderato, non permetiamo ordini di
# acquisto e permettiamo solo di chiudere posizioni aperte se la
# strategia è già a mercato (da un precedenete regime desiderato)
elif regime == 1:
if action == "BOT":
self.invested = False
return []
elif action == "SLD":
if self.invested == True:
self.invested = False
return [order_event]
else:
return []
Questo conclude il codice RegimeHMMRiskManager. Non ci resta che collegare insieme i tre script/moduli precedenti tramite un oggetto Backtest. Il codice completo per questo script può essere trovato, come per il resto dei moduli, alla fine di questo articolo.
In regime_hmm_backtest.py importiamo le classi ExampleRiskManager e RegimeHMMRiskManager. Questo ci permette con un semplice “switch out” dei gestori del rischio per verificare i risultati di differenti backtest:
# regime_hmm_backtest.py
..
..
from datatrader.risk_manager.example import ExampleRiskManager
..
..
from regime_hmm_strategy import MovingAverageCrossStrategy
from regime_hmm_risk_manager import RegimeHMMRiskManager
Nella funzione run iniziamo con specificare il percorso di del file pickle con i dati necessari per la deserializzazione del l modello HMM. Successivamente specifichiamo il gestore dei dati dei prezzi. Impostiamo il flag calc_adj_return su true, in modo che il gestore dei prezzi calcoli e memorizzi l’array dei rendimenti.
In questa fase configuriamo la MovingAverageCrossStrategy con una finestra breve di 10 giorni, una finestra lunga di 30 giorni e una quantità base di azioni SPY pari a 10.000 unità.
Infine deserializziamo il hmm_model tramite pickle e creiamo un’istanza di risk_manager. Il resto dello script è estremamente simile ad altri backtest descritti negli articoli precedente, quindi riportiamo il codice completo solo alla fine dell’articolo.
È semplice “cambiare” i gestori del rischio commentando la riga RegimeHMMRiskManager, sostituendola con la riga ExampleRiskManager e quindi rieseguire il backtest:
def run(config, testing, tickers, filename):
# Impostazione delle variabili necessarie al backtest
pickle_path = "/path/to/your/model/hmm_model_spy.pkl"
..
..
# uso del Use Yahoo Daily Price Handler
start_date = datetime.datetime(2005, 1, 1)
end_date = datetime.datetime(2014, 12, 31)
price_handler = YahooDailyCsvBarPriceHandler(
csv_dir, events_queue, tickers,
start_date=start_date, end_date=end_date,
calc_adj_returns=True
)
# Uso della strategia Moving Average Crossover
base_quantity = 10000
strategy = MovingAverageCrossStrategy(
tickers, events_queue, base_quantity,
short_window=10, long_window=30
)
strategy = Strategies(strategy, DisplayStrategy())
..
..
# Uso del Risk Manager di determinazione del regime HMM
hmm_model = pickle.load(open(pickle_path, "rb"))
risk_manager = RegimeHMMRiskManager(hmm_model)
# Uso di un Risk Manager di esempio
#risk_manager = ExampleRiskManager()
Per eseguire il backtest è necessario aprire il Terminale e digitare quanto segue:
$ python regime_hmm_backtest.py --tickers=SPY
L’output è il seguente:
..
..
---------------------------------
Backtest complete.
Sharpe Ratio: 0.518857928421
Max Drawdown: 0.356537705234
Max Drawdown Pct: 0.356537705234
Risultati della strategia
Costi di transazione
I risultati della strategia qui presentati sono al netto dei costi di transazione. I costi sono simulati utilizzando i prezzi fissi delle azioni statunitensi di Interactive Brokers per le azioni del Nord America . Sono ragionevolmente rappresentativi di ciò che potrebbe essere ottenuto in una vera strategia di trading.
Nessun filtro di rilevamento del regime
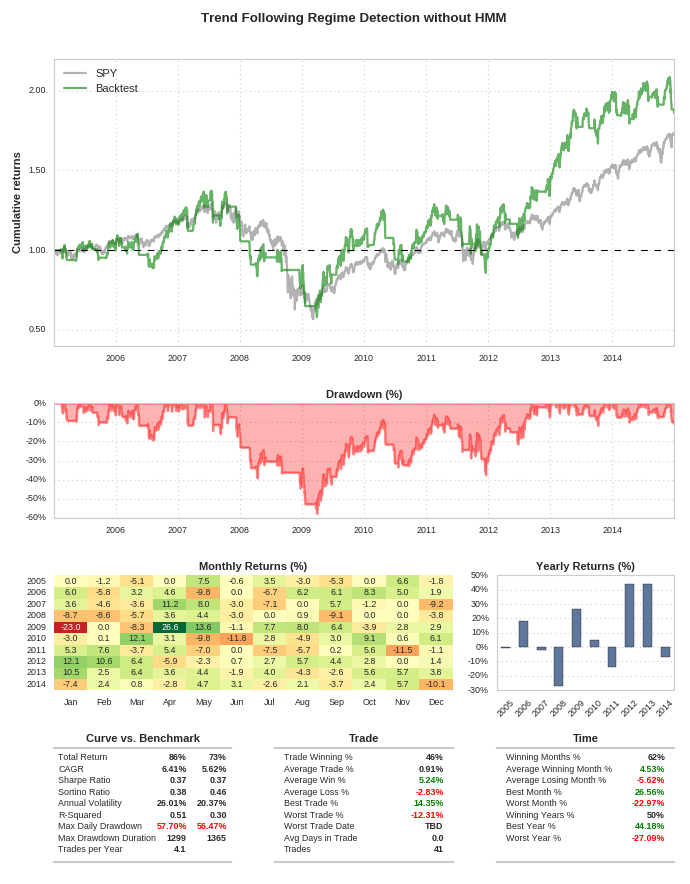
La strategia è progettata per catturare i trend a breve termine dell’ETF SPY. Otteniamo uno Sharpe Ratio di 0,37, cioè stiamo assumendo una notevole quantità di volatilità per generare pochi rendimenti. In effetti il benchmark ha uno Sharpe ratio quasi identico. Il massimo drawdown giornaliero è leggermente superiore al benchmark, ma produce un leggero aumento del CAGR al 6,41% rispetto al 5,62%.
In sostanza, la strategia si comporta come il benchmark buy-and-hold. Questo è prevedibile dato che le medie mobili sono un indicatore di ritardo e, nonostante abbia effettuato 41 operazioni, non evita i grandi movimenti al ribasso. La domanda principale è se un filtro di regime migliorerà la strategia o meno.
Filtro di rilevamento del regime HMM
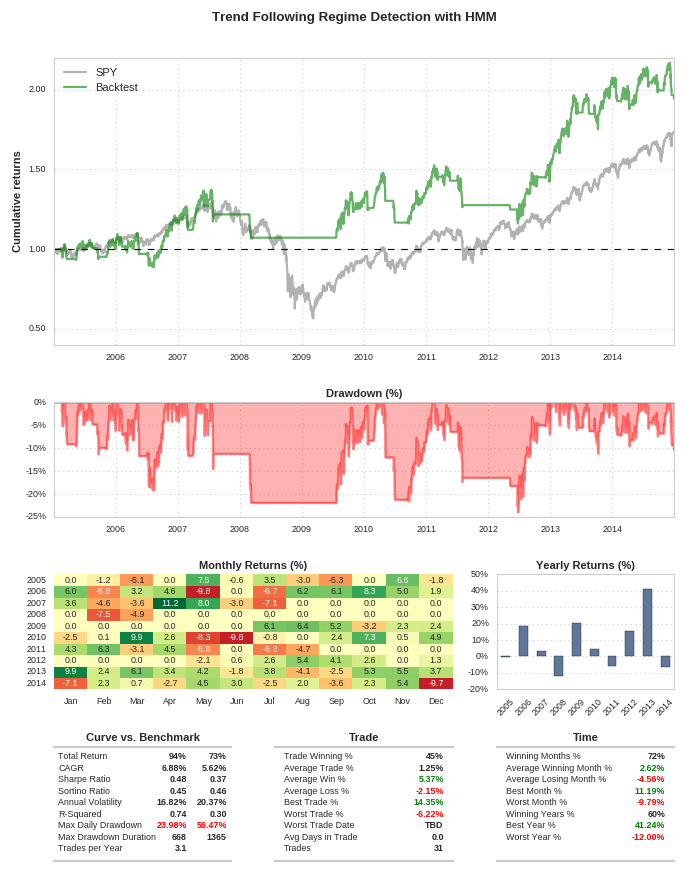
Da notare che l’applicazione del filtro del regime è out-of-sample. Cioè, nessun dato dei rendimenti usato all’interno del backtest è stato usato nell’addestramento del modello Hidden Markov.
La strategia del filtro del regime produce risultati piuttosto diversi. In particolare riduce il drawdown giornaliero massimo della strategia a circa il 24% rispetto a quello prodotto dal benchmark di circa il 56%. Questa è un’ottima riduzione del “rischio”. Tuttavia, lo Sharpe ratio a 0,48 non aumenta di molto rispetto al precedente perché la strategia subisce ancora l’elevata volatilità necessaria per ottenere quei rendimenti.
Il CAGR non vede un grande miglioramento al 6,88% rispetto al 6,41% della strategia precedente, ma il suo rischio è stato leggermente ridotto.
Un problema più significativo è che il numero di operazioni effettuate, ridotte da 41 a 31. Sebbene le operazioni eliminate fossero grandi movimenti al ribasso (e quindi vantaggiosi), significa che la strategia sta facendo meno “scommesse positive” e quindi ha meno validità statistica.
Inoltre, la strategia non ha operato affatto dall’inizio del 2008 alla metà del 2009. Pertanto, la strategia è rimasta effettivamente in ribasso rispetto al precedente high watermark durante questo periodo. Il vantaggio principale, ovviamente, è che non ha perso soldi quando molti altri avrebbero fatto!
Il passaggio “live” di questa strategia deve probabilmente prevedere il periodico addestramento del modello di Markov nascosto dato che le probabilità di transizione dello stato stimate non sono stazionarie nel tempo. In sostanza, l’HMM può solo prevedere le transizioni di stato in base alle precedenti distribuzioni dei rendimenti ricevute come input. Se la distribuzione cambia (ad esempio a causa di un nuovo contesto normativo), il modello dovrà essere riadattato per catturarne il comportamento. La velocità con cui questo deve essere effettuato è, ovviamente, oggetto di potenziali ricerche future!
Codice completo
# regime_hmm_train.py
import datetime
import pickle
import warnings
from hmmlearn.hmm import GaussianHMM
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
import numpy as np
import pandas as pd
import seaborn as sns
def obtain_prices_df(csv_filepath, end_date):
"""
Legge i prezzi dal file CSV e li carica in un Dataframe,
filtra per data di fine e calcola i rendimenti percentuali.
"""
df = pd.read_csv(
csv_filepath, header=0,
names=[
"Date", "Open", "High", "Low",
"Close", "Volume", "Adj Close"
],
index_col="Date", parse_dates=True
)
df["Returns"] = df["Adj Close"].pct_change()
df = df[:end_date.strftime("%Y-%m-%d")]
df.dropna(inplace=True)
return df
def plot_in_sample_hidden_states(hmm_model, df):
"""
Traccia il grafico dei prezzi di chiusura rettificati
mascherati dagli stati nascosti nel campione come
meccanismo per comprendere i regimi di mercato.
"""
# Array con gli stati nascosti previsti
hidden_states = hmm_model.predict(df["Returns"])
# Crea il grafico formattato correttamente
fig, axs = plt.subplots(
hmm_model.n_components,
sharex=True, sharey=True
)
colours = cm.rainbow(
np.linspace(0, 1, hmm_model.n_components)
)
for i, (ax, colour) in enumerate(zip(axs, colours)):
mask = hidden_states == i
ax.plot_date(
df.index[mask],
df["Adj Close"][mask],
".", linestyle='none',
c=colour
)
ax.set_title("Hidden State #%s" % i)
ax.xaxis.set_major_locator(YearLocator())
ax.xaxis.set_minor_locator(MonthLocator())
ax.grid(True)
plt.show()
if __name__ == "__main__":
# Nasconde gli avvisi di deprecazione per sklearn
warnings.filterwarnings("ignore")
# Crea il dataframe SPY dal file CSV di Yahoo Finance e
# formatta correttamente i rendimente per l'uso nell'HMM
csv_filepath = "/path/to/your/data/SPY.csv"
pickle_path = "/path/to/your/model/hmm_model_spy.pkl"
end_date = datetime.datetime(2004, 12, 31)
spy = obtain_prices_df(csv_filepath, end_date)
rets = np.column_stack([spy["Returns"]])
# Crea il Gaussian Hidden markov Model e lo adatta ai
# dati dei rendimenti di SPY, visualizzando il punteggio
hmm_model = GaussianHMM(
n_components=2, covariance_type="full", n_iter=1000
).fit(rets)
print("Model Score:", hmm_model.score(rets))
# Grafico dei valori di chiusura degli stati nascosti del campione
plot_in_sample_hidden_states(hmm_model, spy)
print("Pickling HMM model...")
pickle.dump(hmm_model, open(pickle_path, "wb"))
print("...HMM model pickled.")
# regime_hmm_strategy.py
from collections import deque
import numpy as np
from datatrader.price_parser import PriceParser
from datatrader.event import SignalEvent, EventType
from datatrader.strategy.base import AbstractStrategy
class MovingAverageCrossStrategy(AbstractStrategy):
"""
Requisiti:
tickers - La lista dei simboli dei ticker
events_queue - Il manager della coda degli eventi
short_window - Periodo di lookback per la media mobile breve
long_window - Periodo di lookback per la media mobile lunga
"""
def __init__(
self, tickers,
events_queue, base_quantity,
short_window=10, long_window=30
):
self.tickers = tickers
self.events_queue = events_queue
self.base_quantity = base_quantity
self.short_window = short_window
self.long_window = long_window
self.bars = 0
self.invested = False
self.sw_bars = deque(maxlen=self.short_window)
self.lw_bars = deque(maxlen=self.long_window)
def calculate_signals(self, event):
# Applica SMA al primo ticker
ticker = self.tickers[0]
if event.type == EventType.BAR and event.ticker == ticker:
# Aggiunge l'ultimo prezzo di chiusura ai dati
# delle finestre corta e lunga
price = event.adj_close_price / PriceParser.PRICE_MULTIPLIER
self.lw_bars.append(price)
if self.bars > self.long_window - self.short_window:
self.sw_bars.append(price)
# Sono presenti abbastanza barre per il trading
if self.bars > self.long_window:
# Calcola le medie mobili semplici
short_sma = np.mean(self.sw_bars)
long_sma = np.mean(self.lw_bars)
# Segnali di trading basati sulla media mobile incrociata
if short_sma > long_sma and not self.invested:
print("LONG: %s" % event.time)
signal = SignalEvent(ticker, "BOT", self.base_quantity)
self.events_queue.put(signal)
self.invested = True
elif short_sma < long_sma and self.invested:
print("SHORT: %s" % event.time)
signal = SignalEvent(ticker, "SLD", self.base_quantity)
self.events_queue.put(signal)
self.invested = False
self.bars += 1
# regime_hmm_risk_manager.py
import numpy as np
from datatrader.event import OrderEvent
from datatrader.price_parser import PriceParser
from datatrader.risk_manager.base import AbstractRiskManager
class RegimeHMMRiskManager(AbstractRiskManager):
"""
Utilizza un modello Hidden Markov precedentemente adattato
come meccanismo di rilevamento del regime. Il gestore del
rischio ignora gli ordini che si verificano durante
un regime non desiderato.
Ciò spiega anche il fatto che un'operazione può essere
a cavallo di due regimi separati. Se un ordine di chiusura
viene ricevuto nel regime non desiderato e l'ordine è aperto,
verrà chiuso, ma non verranno generati nuovi ordini fino
al raggiungimento del regime desiderato.
"""
def __init__(self, hmm_model):
self.hmm_model = hmm_model
self.invested = False
def determine_regime(self, price_handler, sized_order):
"""
Determina il probabile regime effettuando una previsione sui rendimenti
dei prezzi di chiusura nell'oggetto PriceHandler e quindi prende
il valore intero finale come "stato del regime nascosto"
"""
returns = np.column_stack(
[np.array(price_handler.adj_close_returns)]
)
hidden_state = self.hmm_model.predict(returns)[-1]
return hidden_state
def refine_orders(self, portfolio, sized_order):
"""
Utilizza il modello di Markov nascosto con i rendimenti percentuali
per determinare il regime corrente, 0 per desiderabile o 1 per
indesiderabile. Ingressi Long seguiti solo in regime 0, operazioni
di chiusura sono consentite in regime 1.
"""
# Determinare il regime previsto HMM come un intero
# uguale a 0 (desiderabile) o 1 (indesiderabile)
price_handler = portfolio.price_handler
regime = self.determine_regime(
price_handler, sized_order
)
action = sized_order.action
# Crea l'evento dell'ordine, indipendentemente dal regime. Sarà
# restituito solo se le condizioni corrette sono soddisfatte.
order_event = OrderEvent(
sized_order.ticker,
sized_order.action,
sized_order.quantity
)
# Se abbiamo un regime desiderato, permettiamo gli ordini di acquisto e di
# vendita normalmente per una strategia di trend following di solo lungo
if regime == 0:
if action == "BOT":
self.invested = True
return [order_event]
elif action == "SLD":
if self.invested == True:
self.invested = False
return [order_event]
else:
return []
# Se abbiamo un regime non desiderato, non permetiamo ordini di
# acquisto e permettiamo solo di chiudere posizioni aperte se la
# strategia è già a mercato (da un precedenete regime desiderato)
elif regime == 1:
if action == "BOT":
self.invested = False
return []
elif action == "SLD":
if self.invested == True:
self.invested = False
return [order_event]
else:
return []
# regime_hmm_backtest.py
import click
import datetime
import pickle
from datatrader import settings
from datatrader.compat import queue
from datatrader.price_parser import PriceParser
from datatrader.price_handler.yahoo_daily_csv_bar import YahooDailyCsvBarPriceHandler
from datatrader.strategy.base import Strategies
from datatrader.position_sizer.naive import NaivePositionSizer
from datatrader.risk_manager.example import ExampleRiskManager
from datatrader.portfolio_handler import PortfolioHandler
from datatrader.compliance.example import ExampleCompliance
from datatrader.execution_handler.ib_simulated import IBSimulatedExecutionHandler
from datatrader.statistics.tearsheet import TearsheetStatistics
from datatrader.trading_session import TradingSession
from regime_hmm_strategy import MovingAverageCrossStrategy
from regime_hmm_risk_manager import RegimeHMMRiskManager
def run(config, testing, tickers, filename):
# Impostazione delle variabili necessarie al backtest
pickle_path = "/path/to/your/model/hmm_model_spy.pkl"
events_queue = queue.Queue()
csv_dir = config.CSV_DATA_DIR
initial_equity = PriceParser.parse(500000.00)
# uso del Use Yahoo Daily Price Handler
start_date = datetime.datetime(2005, 1, 1)
end_date = datetime.datetime(2014, 12, 31)
price_handler = YahooDailyCsvBarPriceHandler(
csv_dir, events_queue, tickers,
start_date=start_date, end_date=end_date,
calc_adj_returns=True
)
# Uso della strategia Moving Average Crossover
base_quantity = 10000
strategy = MovingAverageCrossStrategy(
tickers, events_queue, base_quantity,
short_window=10, long_window=30
)
strategy = Strategies(strategy)
# Uso di un Position Sizer standard
position_sizer = NaivePositionSizer()
# Uso del Risk Manager di determinazione del regime HMM
hmm_model = pickle.load(open(pickle_path, "rb"))
risk_manager = RegimeHMMRiskManager(hmm_model)
# Uso di un Risk Manager di esempio
#risk_manager = ExampleRiskManager()
# Use del Manager di Portfolio di default
portfolio_handler = PortfolioHandler(
PriceParser.parse(initial_equity), events_queue, price_handler,
position_sizer, risk_manager
)
# Uso del componente ExampleCompliance
compliance = ExampleCompliance(config)
# Uso un Manager di Esecuzione che simula IB
execution_handler = IBSimulatedExecutionHandler(
events_queue, price_handler, compliance
)
# Uso delle statistiche di default
title = ["Trend Following Regime Detection with HMM"]
statistics = TearsheetStatistics(
config, portfolio_handler, title,
benchmark="SPY"
)
# Settaggio del backtest
backtest = TradingSession(
config, strategy, tickers,
initial_equity, start_date, end_date, events_queue,
price_handler=price_handler,
portfolio_handler=portfolio_handler,
compliance=compliance,
position_sizer=position_sizer,
execution_handler=execution_handler,
risk_manager=risk_manager,
statistics=statistics,
sentiment_handler=None,
title=title, benchmark='SPY'
)
results = backtest.start_trading(testing=testing)
statistics.save(filename)
return results
@click.command()
@click.option('--config', default=settings.DEFAULT_CONFIG_FILENAME, help='Config filename')
@click.option('--testing/--no-testing', default=False, help='Enable testing mode')
@click.option('--tickers', default='SPY', help='Tickers (use comma)')
@click.option('--filename', default='', help='Pickle (.pkl) statistics filename')
def main(config, testing, tickers, filename):
tickers = tickers.split(",")
config = settings.from_file(config, testing)
run(config, testing, tickers, filename)
if __name__ == "__main__":
main()



