
In questo articolo descriviamo come implementare il backtest di una strategia di pair trading con Python per il mercato degli ETF. L’articolo fa parte della miniserie “Backtest di una strategia di mean reverting con gli ETF”.
Gli articoli che fanno parte di questa serie sono:
- Backtest ETF: Web scraping e Database Sqlite3
- Backtest ETF: Creazione di coppie di Ticker
- Backtest ETF: Mean-reverting con Python
- Backtest ETF: Strategia di Trading con lo Z-score
- Backtest ETF: Pair trading con Python
Concludiamo questa serie di articoli fornendo il codice completo ed eseguibile che include l’uso di query SQL per estrarre i simboli ticker dal database SQLite che abbiamo creato in un precedente articolo.
Backtest di coppie di ETF
In questo esempio abbiamo eseguito una serie di backtest sui simboli ticker del database, basati su una “nicchia” di “minatori d’oro”. In teoria, questa selezione di ticker basata su alcuni criteri di raggruppamento significativi e non arbitrari ci consente di concentrarci su coppie di simboli che hanno maggiori probabilità di avere una cointegrazione delle serie di prezzi statisticamente significativa
Per testare altri gruppi di simboli, dobbiamo semplicemente aggiornare la query SQL secondo un qualsiasi criterio ci interessa. Ad esempio, possiamo modificare la query per selezionare i simboli in base a una “Asset Class” di “Fixed Income”. Le possibili combinazioni sono ovviamente abbondanti e potremmo persino incorporare più criteri contemporaneamente per affinare ulteriormente la nostra ricerca.
Il codice
Quindi, dopo aver seguito le istruzioni per creare il nostro database, possiamo copiare e incollare l’intero codice sottostante in uno script python in modo da eseguire tutti i backtest in una volta sola:
from datetime import datetime
import pandas as pd
import numpy as np
from numpy import log, polyfit, sqrt, std, subtract
import statsmodels.tsa.stattools as ts
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
import pprint
import sqlite3 as db
import yfinance as yf
# imposta il percorso del file del database a cui desideriamo connetterci
# questo è univoco e dipende dove si trova il database SQLite nel sistema locale
database = "C:\Users\Datatrading\sqlite_databases\etfs.db"
# questa è l'istruzione SQL contenente le informazioni riguardo
# a quali ticker vogliamo estrarre dal database
# Ad esempio, ho scelto di estrarre tutti i ticker che hanno
# il loro "Focus" corrispondente a "Silver"
sql = 'SELECT Ticker FROM etftable WHERE Focus = "Silver";'
# crea una connessione al database
cnx = db.connect(database)
cur = cnx.cursor()
# eseque l'istruzione SQL e salva i risultati in una variabile chiamata "tickers"
tickers = pd.read_sql(sql, con=cnx)
# crea una lista vuota
symbList = []
# iterazione sul DataFrame e inserimento dei ticker nella lista
for i in range(len(tickers)):
symbList.append(tickers.ix[i][0])
def get_symb_pairs(symbList):
"""
symbList è una lista di simboli ETF
Questa funzione ha una lista di simboli come paramentro
e restituisce una lista di coppie univoche di simboli
"""
symbPairs = []
i = 0
# scorre la lista e crea tutte le possibili combinazioni di coppie
# di ticker e aggiunge le coppie alla lista "symbPairs"
while i < len(symbList) - 1:
j = i + 1
while j < len(symbList):
symbPairs.append([symbList[i], symbList[j]])
j += 1
i += 1
# scorre la lista di coppie appena creato e rimuove
# tutte le coppie composte da due ticker identici
for i in symbPairs:
if i[0] == i[1]:
symbPairs.remove(i)
# crea una nuova lista vuota per memorizzare solo coppie univoche
symbPairs2 = []
# scorre la lista originale e aggiunge alla nuova lista solo coppie univoche
for i in symbPairs:
if i not in symbPairs2:
symbPairs2.append(i)
return symbPairs2
symbPairs = get_symb_pairs(symbList)
def backtest(symbList):
start_date = '2012-01-01'
end_date = '2020-01-01'
# Download i dati da Yahoo Finance
y = yf.download(symbList[0], start=start_date, end=end_date)
x = yf.download(symbList[1], start=start_date, end=end_date)
# Rinomina le colonne
y.rename(columns={'Adj Close': 'price'}, inplace=True)
x.rename(columns={'Adj Close': 'price'}, inplace=True)
# Verificare che i dataframe sono della stessa lunghezza
min_date = max(df.dropna().index[0] for df in [y, x])
max_date = min(df.dropna().index[-1] for df in [y, x])
y = y[(y.index >= min_date) & (y.index <= max_date)]
x = x[(x.index >= min_date) & (x.index <= max_date)]
############################################################
plt.plot(y.price, label=symbList[0])
plt.plot(x.price, label=symbList[1])
plt.ylabel('Price')
plt.xlabel('Time')
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.show()
#############################################################
sns.jointplot(y=y.price, x=x.price, color='b')
plt.show()
#############################################################
# esegue la regressione dei minimi quadrati ordinari per trovare
# il rapporto di copertura e quindi creare serie di spread
df1 = pd.DataFrame({'y': y['price'], 'x': x['price']})
est = sm.OLS(df1.y, df1.x)
est = est.fit()
df1['hr'] = -est.params[0]
df1['spread'] = df1.y + (df1.x * df1.hr)
##############################################################
plt.plot(df1.spread)
plt.show()
##############################################################
cadf = ts.adfuller(df1.spread)
print('Augmented Dickey Fuller test statistic =', cadf[0])
print('Augmented Dickey Fuller p-value =', cadf[1])
print('Augmented Dickey Fuller 1%, 5% and 10% test statistics =', cadf[4])
##############################################################
def hurst(ts):
"""
Restituisce l'Esponente Hurst Exponent del vettore della serie temporale ts
"""
# Crea il range dei valori ritardati
lags = range(2, 100)
# Calcola l'array delle variance delle differenze dei ritardi
tau = [sqrt(std(subtract(ts[lag:], ts[:-lag]))) for lag in lags]
# Usa una regressione lineare per stimare l'Esponente di Hurst
poly = polyfit(log(lags), log(tau), 1)
# Restituisce l'Esponente di Hurst dall'output di polyfit
return poly[0] * 2.0
##############################################################
print("Hurst Exponent =", round(hurst(df1.spread.to_list()), 2))
##############################################################
# Calcolo della regressione OLS per la serie degli spread e la sua versione ritardata
spread_lag = df1.spread.shift(1)
spread_lag.iloc[0] = spread_lag.iloc[1]
spread_ret = df1.spread - spread_lag
spread_ret.iloc[0] = spread_ret.iloc[1]
spread_lag2 = sm.add_constant(spread_lag)
model = sm.OLS(spread_ret, spread_lag2)
res = model.fit()
halflife = int(round(-np.log(2) / res.params[1], 0))
if halflife <= 0:
halflife = 1
print('Halflife = ', halflife)
##############################################################
meanSpread = df1.spread.rolling(window=halflife).mean()
stdSpread = df1.spread.rolling(window=halflife).std()
df1['zScore'] = (df1.spread - meanSpread) / stdSpread
df1['zScore'].plot()
plt.show()
##############################################################
entryZscore = 2
exitZscore = 0
# calcolo num units long
df1['long entry'] = ((df1.zScore < - entryZscore) & (df1.zScore.shift(1) > - entryZscore))
df1['long exit'] = ((df1.zScore > - exitZscore) & (df1.zScore.shift(1) < - exitZscore))
df1['num units long'] = np.nan
df1.loc[df1['long entry'], 'num units long'] = 1
df1.loc[df1['long exit'], 'num units long'] = 0
df1['num units long'][0] = 0
df1['num units long'] = df1['num units long'].fillna(method='pad')
# calcolo num units short
df1['short entry'] = ((df1.zScore > entryZscore) & ( df1.zScore.shift(1) < entryZscore))
df1['short exit'] = ((df1.zScore < exitZscore) & (df1.zScore.shift(1) > exitZscore))
df1.loc[df1['short entry'], 'num units short'] = -1
df1.loc[df1['short exit'], 'num units short'] = 0
df1['num units short'][0] = 0
df1['num units short'] = df1['num units short'].fillna(method='pad')
df1['numUnits'] = df1['num units long'] + df1['num units short']
df1['spread pct ch'] = (df1['spread'] - df1['spread'].shift(1)) / ((df1['x'] * abs(df1['hr'])) + df1['y'])
df1['port rets'] = df1['spread pct ch'] * df1['numUnits'].shift(1)
df1['cum rets'] = df1['port rets'].cumsum()
df1['cum rets'] = df1['cum rets'] + 1
##############################################################
try:
sharpe = ((df1['port rets'].mean() / df1['port rets'].std()) * sqrt(252))
except ZeroDivisionError:
sharpe = 0.0
plt.plot(df1['cum rets'])
plt.xlabel(symbList[1])
plt.ylabel(symbList[0])
plt.show()
##############################################################
start_val = 1
end_val = df1['cum rets'].iat[-1]
start_date = df1.iloc[0].name
end_date = df1.iloc[-1].name
days = (end_date - start_date).days
CAGR = round(((float(end_val) / float(start_val)) ** (252.0 / days)) - 1, 4)
print("CAGR = {}%".format(CAGR * 100))
for i in symbPairs:
backtest(i)
Speriamo che questo codice possa essere semplice da copiare e incollare per essere eseguito su una macchina locale da chiunque legga questo articolo.
I risultati
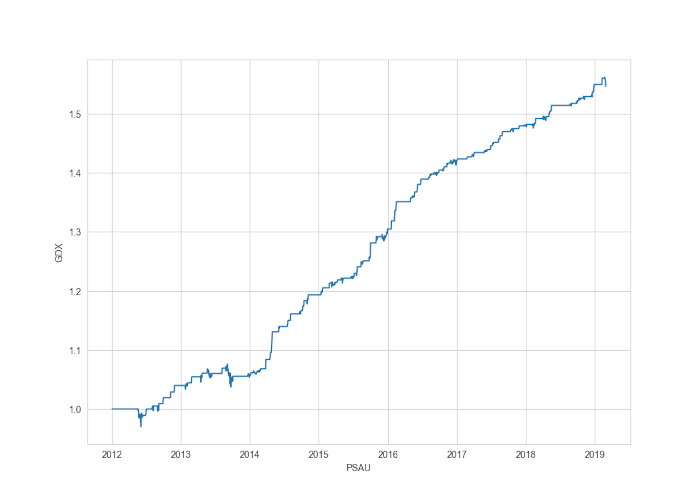
Naturalmente, non abbiamo tenuto conto dei costi di transazione, quindi anche piccoli guadagni potrebbero finire in territorio negativo, a seconda di quante operazioni devono essere effettuate.
Con questa serie abbiamo descritto praticamente tutto quello necessario per implementare uno script eseguibile completamente funzionante in modo da eseguire i test iniziali sulle coppie ETF per identificare eventuali possibili candidati per una strategia di ritorno alla media.



