
Nei precedenti articoli sull’inferenza bayesiana abbiamo introdotto la statistica bayesiana e considerato come dedurre una proporzione binomiale usando il concetto di distribuzione a priori coniugata. Abbiamo descritto come non tutti i modelli possono utilizzare la distribuzione a priori coniugata, quindi il calcolo della distribuzione a posteriori dovrebbe essere approssimato numericamente.
In questo articolo introduciamo la principale famiglia di algoritmi, noti collettivamente come Markov Chain Monte Carlo (MCMC), che ci consentono di approssimare la distribuzione a posteriori calcolata dal teorema di Bayes. In particolare, consideriamo l’algoritmo Metropolis, che è facilmente enunciabile e relativamente semplice da capire. Serve come un utile punto di partenza per conoscere MCMC prima di approfondire algoritmi più sofisticati come Metropolis-Hastings, Gibbs Samplers e Hamiltonian Monte Carlo.
Dopo aver descritto il funzionamento MCMC, descriviamo come utilizzare la libreria open-source PyMC3, che si occupa di implementare molti dettagli sottostanti, permettendoci di concentrarci sulla modellazione bayesiana.
Se non hai ancora guardato i precedenti articoli sulle statistiche bayesiane, ti suggerisco di leggere quanto segue prima di procedere:
- Introduzione alla Statistica Bayesiana
- Inferenza bayesiana di una proporzione binomiale – L’approccio analitico
Obiettivi dell’inferenza bayesiana
Il nostro obiettivo nel campo della statistica bayesiana è produrre strategie di trading quantitative basate su modelli bayesiani. Tuttavia, per raggiungere tale obiettivo, dobbiamo introdurre una ragionevole quantità di teoria sulla statistica bayesiana. Finora abbiamo descritto:
- La filosofia della statistica bayesiana, utilizzando il teorema di Bayes per aggiornare le nostre precedenti convinzioni sulle probabilità dei risultati sulla base di nuovi dati
- Come utilizzare la distribuzione a priori coniugata come mezzo per semplificare il calcolo della distribuzione a posteriori nel caso di inferenza su una proporzione binomiale
In questo articolo descriviamo di MCMC come mezzo per calcolare la distribuzione a posteriori quando la distribuzione a priori coniugata non è applicabile.
Dopo la descrizione del MCMC, in questo articolo consideriamo campionatori più sofisticati utilizzando PyMC3 e quindi li applichiamo a modelli più complessi. In definitiva, vediamo come i nostri modelli sono abbastanza utili da fornire informazioni dettagliate sulla previsione dei rendimenti degli asset. A quel punto siamo in grado di iniziare a costruire un modello di trading a partire dall’analisi bayesiana.
Perché il Markov Chain Monte Carlo?
Nell’articolo precedente abbiamo considerato la distribuzione a priori coniugata, che ha fornito una significativa “scorciatoia” matematica per calcolare la distribuzione a posteriori presente nella regola di Bayes. Una domanda perfettamente legittima a questo punto consiste nel capire perché abbiamo bisogno di MCMC se possiamo semplicemente usare la distribuzione a priori coniugata.
Dobbiamo prevedere il Markov Chain Monte Carlo perchè non tutti i modelli possono essere sinteticamente enunciati in termini di priori coniugati. In particolare, molte situazioni di modellazione più complicate, in particolare quelle relative a modelli gerarchici con centinaia di parametri, sono completamente intrattabili con metodi analitici.
Se ricordiamo la regola di Bayes:
\(\begin{eqnarray}P(\theta | D) = \frac{P(D | \theta) P(\theta)}{P(D)}\end{eqnarray}\)
E’ evidente che dobbiamo calcolare le prove \(P(D)\). Per ottenere ciò dobbiamo valutare il seguente integrale, che integra su tutti i possibili valori di \(\theta\):
\(\begin{eqnarray}P(D) = \int_{\Theta} P(D, \theta) \text{d}\theta\end{eqnarray}\)
Il problema fondamentale consiste nella difficoltà di valutare analiticamente questo integrale e quindi è necessario ricorrere un metodo di approssimazione numerica.
Un ulteriore problema è l’elevato numero dei parametri che i nostri modelli potrebbero richiedere. Ciò significa che le nostre precedenti distribuzioni potrebbero potenzialmente avere un numero elevato di dimensioni, con la conseguenza che anche le distribuzioni a posteriori saranno di dimensioni elevate. In conclusione, si tratta di dover valutare numericamente un integrale in uno spazio dimensionale potenzialmente molto grande.
Questo scenario è spesso spesso descritto come la Maledizione della Dimensionalità. Informalmente, significa che il volume di uno spazio ad alta dimensione è così vasto che tutti i dati disponibili diventano estremamente scarsi all’interno di quello spazio e quindi portano a problemi di rilevanza statistica. In pratica, per acquisire una qualsiasi significatività statistica, il volume dei dati necessari deve crescere in modo esponenziale con il numero delle dimensioni.
Tali problemi sono spesso estremamente difficili da affrontare se non vengono affrontati in modo intelligente. In questa situazione è la motivazione alla base dei metodi Markov Chain Monte Carlo, che permettono una ricerca intelligente all’interno di uno spazio dimensionale elevato, e quindi i modelli bayesiani di dimensioni elevate diventano trattabili.
L’idea di base è campionare dalla distribuzione a posteriori combinando una “ricerca casuale” (l’aspetto Monte Carlo) con un meccanismo per “saltare” in modo intelligente, ma in un modo che alla fine non dipende da dove siamo partiti (una proprietà della Catena di Markov). Quindi i metodi Markov Chain Monte Carlo sono ricerche senza memoria eseguite con salti intelligenti.
Per completezza, il MCMC non è utilizzato solo per eseguire statistiche bayesiane. È anche ampiamente utilizzato nella fisica computazionale e nella biologia computazionale in quanto può essere applicato generalmente all’approssimazione di qualsiasi integrale di alta dimensione.
Algoritmi di Monte Carlo della catena di Markov
Il Markov Chain Monte Carlo è una famiglia di algoritmi, piuttosto che un metodo particolare. In questo articolo ci concentriamo su uno specifico metodo noto come l’algoritmo Metropolis. Nei prossimi articoli prenderemo in considerazione Metropolis-Hastings, Gibbs Sampler, Hamiltonian MCMC e No-U-Turn Sampler (NUTS). Quest’ultimo è effettivamente incorporato in PyMC3, il software che usiamo per dedurre numericamente la nostra proporzione binomiale in questo articolo.
L’algoritmo Metropolis
Il primo algoritmo MCMC considerato in questa serie di articoli è dovuto a Metropolis (1953). Come puoi vedere, è un metodo piuttosto vecchio! Sebbene da allora siano stati apportati miglioramenti sostanziali agli algoritmi di campionamento MCMC, questo metodo è sufficiente per questo articolo. La descrizione di questo semplice metodo ci aiuterà a comprendere i campionatori più complessi descritti negli articoli successivi.
La maggior parte degli algoritmi MCMC seguono il seguente schema (vedi Metodi bayesiani per hacker per maggiori dettagli):
- Iniziare l’algoritmo nella posizione corrente nello spazio dei parametri (\(\theta_{\text{current}}\)).
- Proporre un “salto” in una nuova posizione nello spazio dei parametri (\(\theta_{\text{new}}\)).
- Accettare o rifiutare il salto in modo probabilistico, utilizzando le informazioni precedenti e i dati disponibili.
- Se il salto viene accettato, spostarsi nella nuova posizione e tornare al passaggio 1.
- Se il salto viene rifiutato, restare nell’attuale posizione e tornare al passaggio 1.
- Dopo che si è verificato un determinato numero di salti, restituire tutte le posizioni accettate
La principale differenza tra gli algoritmi MCMC risiede nel modo in cui si salta e nel modo in cui decide se saltare.
L’algoritmo Metropolis utilizza una distribuzione normale per proporre un salto. Questa distribuzione normale ha un valore medio μ che è uguale alla posizione corrente e accetta una “larghezza della proposta” per la sua deviazione standard σ.
La larghezza della proposta è un parametro dell’algoritmo Metropolis e ha un impatto significativo sulla convergenza. Una maggiore larghezza della proposta salterà ulteriormente e coprirà più spazio nella distribuzione a posteriori, ma potrebbe inizialmente perdere una regione di maggiore probabilità. Tuttavia, una larghezza della proposta più piccola non coprirà rapidamente molto spazio e quindi potrebbe richiedere più tempo per convergere.
Una distribuzione normale è una buona scelta per tale distribuzione proposta (per parametri continui) poiché, per definizione, è più probabile che si selezioni punti più vicini alla posizione attuale che più lontani. Tuttavia, occasionalmente si sceglierà punti più lontani, consentendo di esplorare tutto lo spazio.
Una volta che il salto è stato proposto, dobbiamo decidere (in maniera probabilistica) se è una buona mossa saltare alla nuova posizione. Come effettuare questa verifica? Calcoliamo il rapporto tra la distribuzione proposta della nuova posizione e la distribuzione proposta della posizione attuale per determinare la probabilità di spostamento, p:
\(\begin{eqnarray}p = P(\theta_{\text{new}})/P(\theta_{\text{current}})\end{eqnarray}\)
Quindi generiamo un numero casuale uniforme sull’intervallo [0, 1]. Se questo numero è contenuto nell’intervallo [0, p] allora accettiamo il movimento, altrimenti lo rifiutiamo.
Sebbene questo sia un algoritmo relativamente semplice, non è immediatamente chiaro come ci possa aiutare ad evitare il problema del calcolo di un integrale con dimensione elevata dell’evidenza, \(P(D)\).
Come sottolinea Thomas Wiecki nel suo articolo sul campionamento MCMC, in realtà stiamo dividendo il posteriore del parametro proposto per il posteriore del parametro corrente. Utilizzando la regola di Bayes si elimina le prove, \(P(D)\), dal rapporto:
\(\begin{eqnarray}\frac{P(\theta_{\text{new}}|D)}{P(\theta_{\text{current}}|D)} = \frac{\frac{P(D|\theta_{\text{new}})P(\theta_{\text{new}})}{P(D)}}{\frac{P(D|\theta_{\text{current}})P(\theta_{\text{current}})}{P(D)}} = \frac{P(D|\theta_{\text{new}})P(\theta_{\text{new}})}{P(D|\theta_{\text{current}})P(\theta_{\text{current}})}\end{eqnarray}\)
Il lato destro di quest’ultima uguaglianza contiene solo le verosimiglianze e i priori, entrambi facilmente calcolabili. Quindi, dividendo il posteriore in una posizione per il posteriore in un’altra, il più delle volte campionamo regioni con probabilità a posteriori più elevate, in un modo che riflette pienamente la probabilità dei dati.
Introduzione a PyMC3
PyMC3 è una libreria Python che effettua la “Programmazione Probabilistica”. Cioè, possiamo definire un modello probabilistico e quindi eseguire l’inferenza bayesiana sul modello, utilizzando vari tipi di metodi Markov Chain Monte Carlo. In questo senso è simile ai pacchetti JAGS e Stan. PyMC3 ha una lunga lista di collaboratori ed è sempre in fase sviluppo ed aggiornamento.
PyMC3 è stato progettato con una sintassi pulita che consente la specifica del modello estremamente semplice, con un codice “boilerplate” minimale. Esistono classi per tutte le principali distribuzioni di probabilità ed è facile aggiungere altre distribuzioni specialistiche. Ha una suite diversificata e potente di algoritmi di campionamento MCMC, incluso l’algoritmo Metropolis di cui abbiamo discusso sopra, nonché No-U-Turn Sampler (NUTS) . Questo ci permette di definire modelli complessi con molte migliaia di parametri.
PyMC3 utilizza inoltre la libreria Theano di Python, spesso utilizzata per applicazioni di Deep Learning ad alta intensità di CPU/GPU , al fine di massimizzare l’efficienza nella velocità di esecuzione.
Descrivamo Theano negli articoli che trattano del Deep Learning applicato al trading quantitativo.
In questo articolo utilizziamo PyMC3 per eseguire un semplice esempio di deduzione di una proporzione binomiale, sufficiente per descrivere le principali idee, senza impantanarsi nelle specifiche di implementazione di MCMC. Negli articoli successivi esploriamo più funzionalità di PyMC3 quando dobbiamo eseguire l’inferenza su modelli più sofisticati.
Dedurre una proporzione binomiale con Markov Chain Monte Carlo
Come descritto nell’articolo sull’inferenza di una proporzione binomiale usando la distribuzione a priori coniugata , il nostro obiettivo è stimare l’equità di una moneta, eseguendo una sequenza di lanci di monete.
L’equità della moneta è data da un parametro \(\theta \in [0,1]\)
dove \(\theta=0.5\) significa una moneta con la stessa probabilità di avere testa o croce.
Abbiamo descritto la possibilità di utilizzare una distribuzione di probabilità relativamente flessibile, la distribuzione beta, per modellare la nostra precedente convinzione sull’equità della moneta. Abbiamo anche appreso che, utilizzando una funzione di probabilità di Bernoulli per simulare i lanci di monete virtuali con una particolare equità, la nostra convinzione a posteriori avrebbe anche in questo caso la forma di una distribuzione beta. Questo è un esempio di una distribuzione a priori coniugata.
Per essere chiari, questo significa che non è necessario utilizzare MCMC per stimare il posteriore in questo caso particolare poiché esiste già una soluzione analitica in forma chiusa. Tuttavia, la maggior parte dei modelli di inferenza bayesiana non ammette una soluzione in forma chiusa per il posteriore, e quindi è necessario utilizzare MCMC.
Applichiamo MCMC a un caso di cui “conosciamo già la risposta”, in modo da poter confrontare i risultati di una soluzione in forma chiusa e quella calcolata per approssimazione numerica.
Riepilogo dell’inferenza di una proporzione binomiale con la distribuzione a priori coniugata
Nell’articolo precedente abbiamo assunto una particolare convinzione a priori, cioè la moneta fosse probabilmente equa, ma non ne siamo pienamente certi. Questo si traduce nel considerare \(\theta\) con una media \(\mu=0.5\) e una deviazione standard \(\sigma=0.1\).
Una distribuzione beta ha due parametri, \(\alpha\) e \(\beta\), che caratterizzano la “forma” delle nostre convinzioni. Una media \(\mu=0.5\) e una deviazione standard \(\sigma=0.1\) si traduce in \(\alpha=12\) e \(\beta=12\) (vedi l’articolo precedente per i dettagli su questa trasformazione).
Abbiamo quindi effettuato 50 lanci e osservato 10 teste. Quando lo abbiamo inserito nella nostra soluzione in forma chiusa per la distribuzione beta a posteriori, abbiamo ricevuto un posteriore con \(\alpha=22\) e \(\beta=52\). Di seguito la figura che mostra le due distribuzioni:
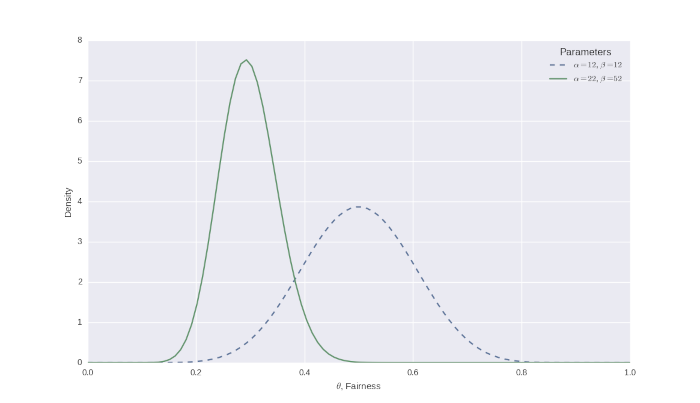
Possiamo intuitivamente vedere come la massa della probabilità si è spostata drasticamente a più vicino a 0,2, che è l’equità del campione dai nostri lanci. Da notare anche che il picco è diventato più stretto poiché siamo ora abbastanza fiduciosi nei nostri risultati, dopo aver effettuato 50 lanci.
Dedurre una proporzione binomiale con PyMC3
Ora eseguiremo la stessa analisi utilizzando invece il metodo numerico Markov Chain Monte Carlo. Innanzitutto, dobbiamo installare PyMC3:
pip install --process-dependency-links git+https://github.com/pymc-devs/pymc3
Una volta installato, dobbiamo successivamente importare le librerie necessarie, che includono Matplotlib, Numpy, Scipy e lo stesso PyMC3. Abbiamo anche impostato lo stile grafico dell’output di Matplotlib in modo che sia simile alla libreria grafica ggplot2:
import matplotlib.pyplot as plt
import numpy as np
import pymc3
import scipy.stats as stats
plt.style.use("ggplot")
Il prossimo passo è impostare i nostri parametri precedenti, così come il numero di prove di lancio di monete effettuate e le teste restituite. Specifichiamo anche, per completezza, i parametri della distribuzione beta calcolata analiticamente a posteriori, che utilizzeremo per il confronto con il nostro approccio MCMC. Inoltre precisiamo di voler effettuare 100.000 iterazioni dell’algoritmo Metropolis:
# Parameter values for prior and analytic posterior
n = 50
z = 10
alpha = 12
beta = 12
alpha_post = 22
beta_post = 52
# How many iterations of the Metropolis
# algorithm to carry out for MCMC
iterations = 100000
Ora definiamo la nostra distribuzione beta a priori e il modello di probabilità di Bernoulli. PyMC3 ha un’API molto pulita per eseguire questa operazione. Si usa un context with di Python per assegnare tutti i parametri, le dimensioni dei passaggi e i valori iniziali a un’istanza pymc3.Model (che denominiamo basic_model, come dal tutorial PyMC3).
In primo luogo, specifichiamo il parametro theta come distribuzione beta, prendendo i valori a priori alpha e beta come parametri. Ricordiamo che i specifici valori di \(\alpha=12\) e \(\beta=12\) implicano una media a priori \(\mu=0.5\) e una deviazione standard a priori \(\sigma=0.1\).
Definiamo quindi la funzione di verosimiglianza di Bernoulli, specificando il parametro di equità p=theta, il numero di prove n=ne le teste osservate observed=z, il tutto ricavato dai parametri sopra specificati.
A questo punto possiamo trovare un valore di partenza ottimale per l’algoritmo Metropolis utilizzando l’ottimizzazione PyMC3 Maximum A Posteriori (MAP) (ne parliamo nel dettagli negli articoli successivi). Infine specifichiamo il campionatore Metropolis da utilizzare e quindi i risultati effettivi sample(..). Questi risultati sono memorizzati nella variabile trace:
# Use PyMC3 to construct a model context
basic_model = pymc3.Model()
with basic_model:
# Define our prior belief about the fairness
# of the coin using a Beta distribution
theta = pymc3.Beta("theta", alpha=alpha, beta=beta)
# Define the Bernoulli likelihood function
y = pymc3.Binomial("y", n=n, p=theta, observed=z)
# Carry out the MCMC analysis using the Metropolis algorithm
# Use Maximum A Posteriori (MAP) optimisation as initial value for MCMC
start = pymc3.find_MAP()
# Use the Metropolis algorithm (as opposed to NUTS or HMC, etc.)
step = pymc3.Metropolis()
# Calculate the trace
trace = pymc3.sample(iterations, step, start, random_seed=1, progressbar=True)
Si noti come la specifica del modello tramite l’API PyMC3 sia quasi simile alla specifica matematica effettiva del modello, con un codice “boilerplate” minimale. Dimostreremo la potenza di questa API negli articoli successivi quando arriveremo a specificare alcuni modelli più complessi.
Ora che il modello è stato specificato e campionato, desideriamo tracciare i risultati. Creiamo un istogramma dalla traccia (l’elenco di tutti i campioni accettati) del campionamento MCMC utilizzando 50 bin. Tracciamo quindi le distribuzioni beta analitiche precedenti e posteriori utilizzando il metodo stats.beta.pdf(..) di SciPy. Infine, aggiungiamo alcune etichette al grafico e lo visualizziamo:
# Plot the posterior histogram from MCMC analysis
bins=50
plt.hist(
trace["theta"], bins,
histtype="step", normed=True,
label="Posterior (MCMC)", color="red"
)
# Plot the analytic prior and posterior beta distributions
x = np.linspace(0, 1, 100)
plt.plot(
x, stats.beta.pdf(x, alpha, beta),
"--", label="Prior", color="blue"
)
plt.plot(
x, stats.beta.pdf(x, alpha_post, beta_post),
label='Posterior (Analytic)', color="green"
)
# Update the graph labels
plt.legend(title="Parameters", loc="best")
plt.xlabel("$\\theta$, Fairness")
plt.ylabel("Density")
plt.show()
Applied logodds-transform to theta and added transformed theta_logodds to model.
[----- 14% ] 14288 of 100000 complete in 0.5 sec
[---------- 28% ] 28857 of 100000 complete in 1.0 sec
[---------------- 43% ] 43444 of 100000 complete in 1.5 sec
[-----------------58%-- ] 58052 of 100000 complete in 2.0 sec
[-----------------72%------- ] 72651 of 100000 complete in 2.5 sec
[-----------------87%------------- ] 87226 of 100000 complete in 3.0 sec
[-----------------100%-----------------] 100000 of 100000 complete in 3.4 sec
Chiaramente, il tempo di campionamento dipenderà dalla velocità del tuo computer. L’output grafico dell’analisi è riportato nella seguente immagine:
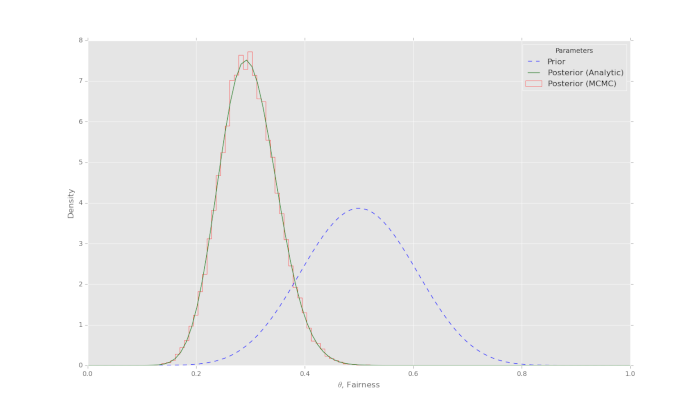
In questo particolare caso di modello a parametro singolo, con 100.000 campioni, la convergenza dell’algoritmo Metropolis è estremamente buona. L’istogramma segue da vicino la distribuzione calcolata analiticamente a posteriore, come da previsione. In un modello relativamente semplice come questo non abbiamo bisogno di calcolare 100.000 campioni ma ne sarebbero sufficienti molti meno. Tuttavia, sottolinea la convergenza dell’algoritmo Metropolis.
Possiamo anche considerare un concetto noto come traccia, cioè il vettore dei campioni prodotti dalla procedura di campionamento MCMC. Possiamo usare il metodo traceplot per tracciare sia una stima della densità del kernel (KDE) dell’istogramma visualizzato sopra, sia la traccia.
Il trace plot è estremamente utile per valutare la convergenza di un algoritmo MCMC e se è necessario escludere un periodo di campioni iniziali (noto come burn-in). Descriviamo la traccia, il burn-in e altri problemi di convergenza in altri articoli dove studiamo campionatori più sofisticati. Per produrre la traccia chiamiamo semplicemente traceplot con la variabile trace:
# Show the trace plot
pymc3.traceplot(trace)
plt.show()
Ecco il tracciato completo:
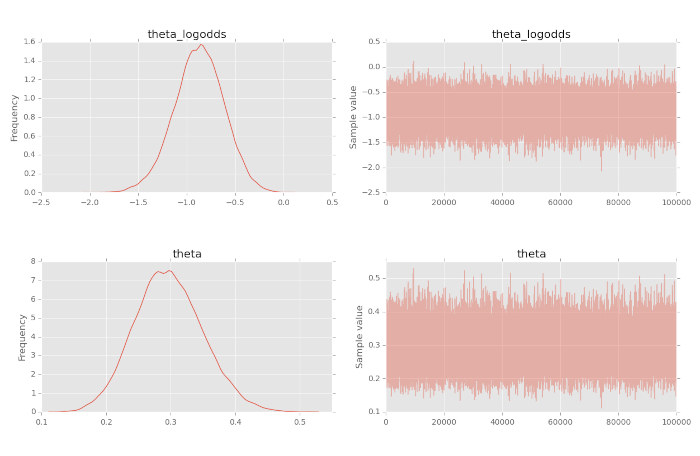
Da notare come la stima di KDE della convinzione a posteriori nell’equità riflette sia la convinzione a priori di \(\sigma=0.5\) che i nostri dati con una correttezza campionaria di \(\sigma=0.2\). Inoltre possiamo vedere che la procedura di campionamento MCMC è “convergente alla distribuzione” poiché la serie di campionamento sembra stazionaria.
In casi più complicati, che esaminiamo in altri articoli, dobbiamo considerare un periodo di “burn in” così come i “sottili” risultati per rimuovere l’autocorrelazione, entrambi i quali migliorano la convergenza.
Per completezza, di seguito l’elenco completo:
import matplotlib.pyplot as plt
import numpy as np
import pymc3
import scipy.stats as stats
plt.style.use("ggplot")
# Parameter values for prior and analytic posterior
n = 50
z = 10
alpha = 12
beta = 12
alpha_post = 22
beta_post = 52
# How many iterations of the Metropolis
# algorithm to carry out for MCMC
iterations = 100000
# Use PyMC3 to construct a model context
basic_model = pymc3.Model()
with basic_model:
# Define our prior belief about the fairness
# of the coin using a Beta distribution
theta = pymc3.Beta("theta", alpha=alpha, beta=beta)
# Define the Bernoulli likelihood function
y = pymc3.Binomial("y", n=n, p=theta, observed=z)
# Carry out the MCMC analysis using the Metropolis algorithm
# Use Maximum A Posteriori (MAP) optimisation as initial value for MCMC
start = pymc3.find_MAP()
# Use the Metropolis algorithm (as opposed to NUTS or HMC, etc.)
step = pymc3.Metropolis()
# Calculate the trace
trace = pymc3.sample(iterations, step, start, random_seed=1, progressbar=True)
# Plot the posterior histogram from MCMC analysis
bins=50
plt.hist(
trace["theta"], bins,
histtype="step", normed=True,
label="Posterior (MCMC)", color="red"
)
# Plot the analytic prior and posterior beta distributions
x = np.linspace(0, 1, 100)
plt.plot(
x, stats.beta.pdf(x, alpha, beta),
"--", label="Prior", color="blue"
)
plt.plot(
x, stats.beta.pdf(x, alpha_post, beta_post),
label='Posterior (Analytic)', color="green"
)
# Update the graph labels
plt.legend(title="Parameters", loc="best")
plt.xlabel("$\\theta$, Fairness")
plt.ylabel("Density")
plt.show()
# Show the trace plot
pymc3.traceplot(trace)
plt.show()
Prossimi passi
In questo articolo abbiamo descritto le basi di MCMC, nonché un metodo specifico noto come algoritmo Metropolis, applicato per dedurre una proporzione binomiale.
Tuttavia, come discusso in precedenza, PyMC3 utilizza un campionatore MCMC molto più sofisticato noto come No-U-Turn Sampler (NUTS). Per capire la logica di questo campionatore, alla fine dobbiamo considerare ulteriori tecniche di campionamento come Metropolis-Hastings, Gibbs Sampling e Hamiltonian Monte Carlo (su cui si basa NUTS).
Vogliamo anche iniziare ad applicare le tecniche di Programmazione Probabilistica a modelli più complessi, come i modelli gerarchici. Questo a sua volta ci aiuterà a produrre sofisticate strategie di trading quantitativo.
Riferimenti
- Davidson-Pilon, C. et al (2016) “Probabilistic Programming & Bayesian Methods for Hackers”, http://camdavidsonpilon.github.io/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/
- Duane, S. et al (1987) “Hybrid Monte Carlo”, Physics Letters B 195 (2): 216–222
- Gelfand, A.E. and Smith, A.F.M. (1990) “Sampling-based approaches to calculating marginal densities”, J. Amer. Statist. Assoc., 85, 140, 398-409.
- Geman, S. and Geman, D. (1984) “Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images.”, IEEE Trans. Pattern Anal. Mach. Intell., 6, 721-741.
- Gelman, A. et al (2013) Bayesian Data Analysis, 3rd Edition, Chapman and Hall/CRC
- Hastings, W. (1970) “Monte Carlo sampling methods using Markov chains and their application”, Biometrika, 57, 97-109.
- Hoffman, M.D., and Gelman, A. (2011) “The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo, arXiv:1111.4246 [stat.CO]
- Kruschke, J. (2014) Doing Bayesian Data Analysis, Second Edition: A Tutorial with R, JAGS, and Stan, Academic Press
- Metropolis, N. et al (1953) “Equations of state calculations by fast computing machines”, J. Chem. Phys., 21, 1087-1092.
- Robert, C. and Casella, G. (2011) “A Short History of Markov Chain Monte Carlo: Subjective Recollections from Incomplete Data”, Statistical Science 0, 00, 1-14.
- Wiecki, T. (2015) “MCMC sampling for dummies”, http://twiecki.github.io/blog/2015/11/10/mcmc-sampling/


